


search製品名・スペックから検索








高性能なNVIDIA DGX-1が画像認識の発展を支える
中部大学 工学部 情報工学科 様
中部大学の山下隆義准教授は、自動運転技術にも 利用されている画像認識のスペシャリストだ。 GPUコンピューティングが必要不可欠な存在となっている画像認識の分野において、「NVIDIA DGX-1」は 山下准教授の研究を強力にサポートしている。

中部大学は、愛知県春日井市のキャンパスに文理7つの学部が集結する私立の総合大学。1964年に開校した中部工業大学が前身となることから、中心となる工学部は8つの学科を有し、2018年4月には新たに宇宙航空理工学科が誕生する予定だ。
工学部情報工学科の山下隆義准教授は、画像処理やパターン認識を専門分野としており、物体検出や物体追跡、ジェスチャー認識などの研究を進めている。同大学に所属するまでは一般企業に勤めており、画像認識のソフトウェア開発に従事。最近のデジタルカメラやスマートフォンでは標準機能として搭載されている撮影時の顔検出機能を手掛けていた。

中部大学 工学部 情報工学科 准教授 山下隆義氏
「画像認識やコンピュータービジョンの研究は、企業にいる頃からずっと続けていました。そんななか、画像認識の分野における大きなブレイクスルーとなったのが、2012年に登場したディープラーニングを活用する新たな手法。この手法によって画像認識の性能は飛躍的に向上したわけですが、この手法に興味を持ったことから、2014年に大学に移って研究の中心に据えるようになりました」(山下准教授)
また、ディープラーニングを活用した手法において、大きなポイントとなったのが「GPUによる高速化」だ。そもそも、それまでの画像認識の研究でGPUを利用する人はほとんどいなかったのだが、この手法によって「GPUを使えば処理を高速化できる」ことが判明。これにより、画像認識の分野でもGPUはなくてはならない存在となり、山下准教授もGPUコンピューティングを手掛けるようになったという経緯がある。
「GPUがあるとないとでは、その処理速度は雲泥の差です。体感的には10倍程度違うイメージだったでしょうか。そういった意味でも、研究のスピード感は圧倒的に速くなりました」(山下准教授)
対象の特徴を捉える計算にGPUの高い処理能力を活用

中部大学の外観
現在、山下准教授がメインで進めている研究は2つある。ひとつは、近年注目を集めている自動運転技術のための「画像認識」。この研究では、画像を解析して写っている物体が歩行者なのか自動車なのかを識別するほか、人物であればそれが男性なのか女性なのか、子供なのか年配なのか、あるいはどちらを向いているのかといった細かな属性の認識も目指している。さらに、写真から識別した対象を「人物は赤、自動車は青、道路は紫、歩道はピンク」といった感じで色分けし、塗り絵のようなイメージで属性をラベリングしていく「セマンティック・セグメンテーション」にも積極的に取り組んでいる。これらの結果がディープラーニングの学習データとして蓄積されることで、その次のステップにも役立っていくわけだ。
もうひとつは、画像処理をロボットへ応用する研究だ。そもそも、ロボットを動かす場合には、人間の目に相当する機能が必要となる。そこで、画像処理によってさまざまな情報を読み取り、その役割を担おうというわけだ。例えば、写っている商品を認識したり、物を取る際の位置情報を検出したりするほか、その物の取り方を判定するときなどにも活用される。そして、この画像認識や画像処理において、画像の各所が持つ特徴を捉える計算に、GPUコンピューティングが活用されている。
「画像に写っている物体が何であるかを認識する場合、例えば人物であれば、人間が持つ形状や色などの特徴をチェックしていくことで識別していきます。ただし、この処理はひとつひとつが小さな計算でも、さまざまな特徴を全てチェックしていくためには、同様の処理を何度も繰り返す必要があります。そうなると、全体としては非常に膨大な計算量となるわけです。そのため、認識する範囲を広げたり精度を上げたりすれば、処理を行うマシンにはさらに高いスペックが求められます」(山下准教授)
また、上記のように画像認識の処理は「同様の処理を何度も繰り返す」ことが特徴のひとつとなるため、並列計算が得意なGPUにとってとても有利な状況といえる。こういった背景から、山下准教授は世界初のDeepLearning専用スーパーコンピュータ「NVIDIADGX-1」を2017年2月に導入した。
8枚のGPUを使い分けて研究の効率アップをはかる
NVIDIADGX-1を導入するまで、山下准教授は市販のパソコンとGPUを組み合わせて研究を進めていた。そのマシンで非常に計算量の多いセマンティック・セグメンテーションの処理を実行すると、計算が完了するまでに約1ヵ月かかっていたという。しかし、NVIDIADGX-1の性能をフルに利用すれば、同じ処理を4~5日で完了することが可能。このスピード感はまさに圧倒的で、研究のサイクルは大きく向上した。
「NVIDIADGX-1の性能にはとても満足しています。ただ、実をいうと今までGPUの処理速度に大きな不満を感じていたわけではありません。なぜなら、従来の感覚では『マシンのスペックに合わせて研究や実験内容を選んでいた』からです。つまり、処理に2~3ヵ月もかかるような研究は、最初から対象として排除している状況だったわけです。だからこそ、GPUの性能に不満を感じることが少なかったといえます。しかし、NVIDIADGX-1の導入によって、これまで排除してきた研究も対応可能になりました。そういった意味では、研究の幅が広がったといって良いでしょう」(山下准教授)
また、NVIDIA DGX-1は1台に8枚のGPUを搭載していることから、GPUを使い分けることで複数問題の同時計算が可能な点も魅力のひとつといえる。例えば、1つの研究において8種類のパラメータを設定した共通の実験を同時に計算することが可能。セマンティック・セグメンテーションのような負荷の高い計算には8枚のGPUを1つの処理にフル活用し、軽い計算であれば複数の処理にGPUを振り分けて同時に計算するという、1台での使い分けが研究の効率アップにつながっているわけだ。山下准教授は「感覚的に倍ぐらいのスピード感が得られていると思います」と笑みを浮かべる。
多くのソフトは動作確認済み手間なく利用できる点も魅力
性能面以外にも、山下准教授は使い勝手の良さにメリットを感じている。先ほど紹介したように、山下准教授はNVIDIADGX-1の導入前に市販のパソコンとGPUを利用していたわけだが、研究に必要なフリーのソフトウェアやライブラリのインストールは当然自前で行う必要がある。山下准教授の研究室では約30台のパソコンを所持しているそうだが、マシンが1台増えるたびにその作業を行ってきたわけだ。
もちろん、その作業自体がそれなりの手間となるわけだが、ここでさらに問題となっていたのが、同じソフトウェアやライブラリをインストールしてもマシンが異なると「確実に動作する保証はない」ということ。導入時期によってマシンのパーツやソフトウェアのバージョンなどが異なることから、セットアップの変更が必要な場合も往々にして出てくるわけだ。この作業には少なくとも1日、場合によっては1週間かかるケースもあったそうで、その手間と時間が大きなボトルネックとなっていた。
「その点、NVIDIA DGX-1はディープラーニングに関連する多くのフレームワークやライブラリの動作確認を行っています。インストール後にすぐ利用できるため、セットアップの手間を大きく削減できました。効率的な運用サポートの観点から、この対応は非常に魅力的です」(山下准教授)
NVIDIA DGX-1から大きな恩恵を受けている山下准教授が、次に目指すのは「動画解析」だ。山下准教授によれば、画像解析はすでに高いレベルにまで到達しているものの、動画解析はまだまだ難しい状況だという。なぜなら、例えば映像が動いている場合、その動きが撮影者によるものなのか、それとも撮影対象によるものなのかを認識する必要が出てくるなど、これまで以上にチェックすべきポイントが増えてくるからだ。これは当然、これまで以上に計算量が増えることを意味し、動画解析ではさらなるマシン性能の向上が求められることとなる。
「自動運転技術では、瞬間的な計算に対応する必要もあります。より短時間で処理できる負荷の軽い計算をいかにして実現するか。ハードウェアとともに、ソフトウェアやアルゴリズムの進歩も重要となるでしょう。NVIDIA DGX-1によって環境がさらに整ってきたので、今後はもっと研究を加速していきたい考えです」(山下准教授)
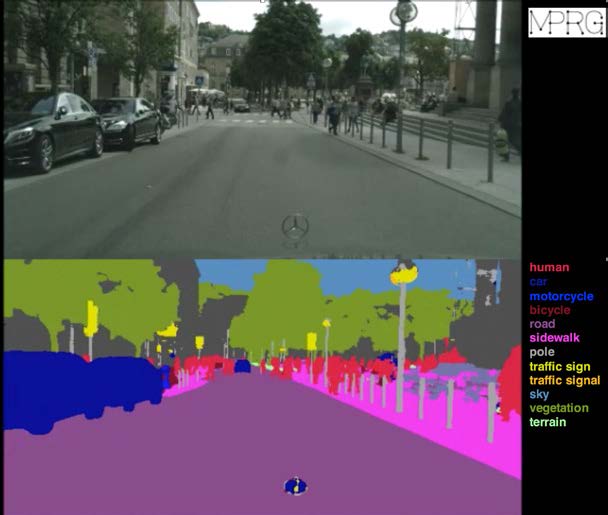
「セマンティック・セグメンテーション」のイメージ。上段の画像が、解析によって下段のように色分けされる

Tesla P100を8基搭載したNVIDIA DGX-1
![]()
中部大学の使用モデル

NVIDIA DGX-1
NVIDIA自社設計のNVLink対応マザーボードに、最新アーキテクチャPascal世代のGPU「TESLA P100」を8基搭載した世界初のディープラーニング専用スーパーコンピュータ。TESLAP100は、倍精度で5.3TFLOPS、単精度で10.6TFLOPS、半精度で21.2TFLOPSの演算性能を実現する。


