
大規模AI開発には
ハイスペックなマシンが
必要不可欠
AIの爆発的な進展と
技術革新
技術開発の活発化による
開発競争の激化
日々変化するAI分野において、ファインチューニングのサイクルを効率化するために
最適なシステム環境を構築する必要があります。
GPUの
選び方
メモリ&
ストレージ
の選び方
その他
検討事項
AI開発競争の鍵となるGPU
- 使いたいAIモデルの大きさや必要なデータ量によってそれらをカバーするGPUのメモリ容量のGPUを選定
- 想定されるGPUメモリ使用量に対して20〜30%程度の余裕を持ったGPUメモリを選定
- 大規模モデルを扱う場合は、80GB以上のGPUメモリを搭載したGPUやマルチGPU構成を検討
- 消費電力を抑えながら帯域幅と容量が倍増し、並列演算能力が高い最新のDRAM規格(GDDR7)を検討
NVIDIA Blackwell Tensor
コア第 5 世代
Blackwellアーキテクチャは
学習・推論を高速化
AIモデルのトレーニングと推論において、より高速で正確な計算を実現。
コスト、スペックのバランスが取れた最適なGPUです。

30倍の高速化
Blackwellアーキテクチャは、GPT-MoE-1.8Tのような大規模
モデルで前世代のAdaLovelaceと比較して30倍の高速化を実現。
第5世代Tensorコア
新世代のTensorコアでパフォーマンス向上。
より高速で正確な計算を実現。
FP4およびFP6演算が新たに正式サポート
従来よりもはるかに低い精度での
高速かつ効率的な推論が可能。
GDDR7メモリによりメモリ帯域幅の向上
大規模な生成AIモデルでも
安定して高速な処理が可能
メモリの選び方

- 64GB〜512GB以上
(GPUメモリに対して1.5〜2倍程度)
大規模データセットの処理に対応
テラバイト(TB)やペタバイト(PB)レベルの膨大なデータや複雑なモデルの学習時に発生する
メモリ不足の問題を効果的に回避できます。
ストレージの選び方

-
NVMe M.2(1TB以上)
※データのリードライとのボトルネック解消のため、
NVMe M.2を推奨
高速なリードライトで
学習効率を向上
AI開発にNVMe SSDを導入することで、HDDに比べてデータ処理の効率が数倍向上するため、
より短時間で高精度なモデルを構築することが可能となります。
その他検討事項
-
冷却性能
ケース内部のエアフローが最適化された設計で、吸気と排気のバランスが良いと高廃熱GPUを効率よく冷却し安定稼働します。
-
消費電力
特にGPUは、AIや科学計算などの高性能タスクにおいて電力を消費します。GPUを搭載するマシンは、GPUの性能に応じて消費電力が上がり電力供給能力が必要になります。
また、複数のGPUを搭載する場合、高消費電力に対応できるPSUであれば安定して稼働します。 -
拡張性
メモリ、ストレージ、GPU、外部接続など多数の要素について現在のニーズだけでなく、将来のアップグレードや変更において、拡張性を考慮した設計であれば、長期的に使い続けることができます。
-
セキュリティ対策
デスクサイドに設置する場合、機密データの流出を防いだり高価なGPUを確実に保護するため、物理的な持ち出しができないようなセキュリティ対策を検討する。
-
ソフトウェア整合性
ハードウェアがソフトウェアとシームレスに連携し、最適なパフォーマンスを発揮できるように設計されていることが重要です。
-
設置場所(騒音)
高負荷時に大量の熱や騒音を発生させるGPUの特性から、居室に設置する場合は騒音が少ない場所を選び、通気性が良く安定した電源供給が可能な場所を考慮することで性能を最大限に引き出します。
 は
は
AI開発向けのハードウェアを検討する
お客様の検討課題やニーズをもとに設計され
AI開発の高速化
を支援します
最大4枚のGPUを
搭載可能な
AIワークステーション

DeepLearningSTATIONIIは、LLMなど大規模AI学習での利用を想定した
Blackwellアーキテクチャ「RTX PRO 6000シリーズ」を最大4枚搭載し、優れた冷却性能と静音設計で、快適な作業環境を提供。
高性能で拡張性が高く、研究開発や産業用途に最適です。
生成 AI
LLM 推論
テキスト生成
チャットボット
画像生成
画像解析
3Dシミュレーション
生体分子の生成
分子ドッキング
タンパク質の予測

搭載可能な最新GPU
GPUカードについての詳細はこちら
最大4基搭載
RTX PRO™ 6000 Blackwell Max-Q
単精度性能:110 TFLOPS
AI TOPS:3,511 AI TOPS
RTコア:333 TFLOPS
最大消費電力:300W

最大1基搭載
RTX PRO™ 6000 Blackwell Workstation
単精度性能:125 TFLOPS
AI TOPS:4,000 AI TOPS
RTコア:380 TFLOPS
最大消費電力:600W
6つの製品特徴
01DESIGN
100V環境で動作可能なDualPSU設計
独自設計により、2つの電源ユニットを搭載出来る「Dual PSU設計」を採用。100Vx2入力で理論値3000Wの消費電力までに対応し、特別な電源環境を備えていない居室でのハイエンドマルチGPU環境を実現します。

02MOUNTED
最大4基のハイエンドGPUを
搭載
Blackwell世代のプロフェッショナルGPUを4枚実装可能。2台のPSUから供給される安定した電源環境と、エアフローを考えつくしたフロント吸気、リア&トップ排気のケースデザインが高廃熱GPUを効率よく冷却し安定稼働を実現します。
※4GPU静音でも温度が上がらず安全に使用可能

03SECURITY
高い拡張性とセキュリティ性を実現
フロントアクセス可能な鍵付きの3.5インチストレージベイを2基、内部には2.5インチインターナルスロットを4基装備。システム領域とデータ領域を分けてRAID構築するなど、フレキシブルで拡張性の高い使い方が可能。また、サイドパネルはケンジントンロックに対応しており、貴重なデータと高価なGPUを確実に保護します。

04MOUNTED
水冷Intel Xeon W3500 Series
CPU搭載
シングルソケットで最大 60 個のメニーコア環境を実現するIntel Xeon W-3500シリーズを搭載しています。複雑な設計、シミュレーション、大規模なビデオエフェクト、AI ワークロードに最適な、拡張可能なタワー型モデルで最高レベルのワークステーション・パフォーマンスとスケーラビリティーを実現します。

05OPTION
ラックマウントにも対応
独オプションの 19インチラック マウントキットを装着することで6Uサイズで19インチラックへの搭載が可能です。サーバールームやデータセンターなど設置場所を選びません。

06APPジーデップオリジナル
AI開発環境・「G-Suite」をプレインストール
G-Suite(ジー・スイート)は、Deep Learning の主要なフレームワークを、各世代のGPU に最適化してビルドしたソフトウェア群を、更に発展させたOS ネイティブ環境+コンテナ環境のハイブリッドアプリケーションリソースマネージメントツールです。

公的第三者機関で
動作音のテスト検証

「DeepLearningSTATIONII」は品質へのこだわりから、
公的第三者機関の無響室で動作音の測定を行っております。
フル負荷をかけた状態で測定した結果は以下の数値であり、
日常会話の妨げにならず、居室で十分利用可能な静音性能を
しめす結果となりました。
測定結果
47db

測定条件
- 温度
- 24℃
- 湿度
- 45%
- 気圧
- 1019 hPa
- 測定点
- 依頼品の表面中心より水平方向1.0m
- マイクロホン
- B&K 4190
測定結果
| 作動条件 | A特性時間平均 音圧レベル [dB] |
|
|---|---|---|
| GPU条件 | 負荷条件 | 測定点1(正面) |
| 4枚 | ||
| アイドリング | 45.8 | |
| フル負荷 | 46.9 | |

ベンチマークレポート
NVIDIAのBlackwell世代では、4ビット浮動小数点(FP4)精度の量子化対応が正式にサポートされ、
従来よりもはるかに低い精度での高速かつ効率的な推論が可能となりました。
これにより、特に画像生成タスクにおける処理速度と精度が著しく向上しました。
システム要件
- ベンチマーク機種
- DeepLearningBOXⅢ
- GPU
- GPUはそれぞれ1基
- CPU
- 1x Intel Xeon w7-3565X
- マザーボード
- ASUS-PRO/WS/W790E-SAGE/SE
(Intel W790 チップセット) - MEM
- 128GB DDR5-4800 ECC
- ストレージ
- M.2 NVMe SSD 1TB
- 電源
- HX1500i × 2

Ada Lovelace
NVIDIA RTX 6000Ada |

Blackwell
RTX PRO™ 6000 Blackwell Max-Q |
|
|---|---|---|
| メモリーのタイプ | GDDR6 | GDDR7 |
| 最大メモリー容量 | 48 GB | 96 GB |
| メモリーのバスの幅 | 384 Bit | 512 Bit |
| メモリー周波数 | 2500 MHz | 1750 MHz |
| メモリー帯域幅 | 960.0 GB/s | 1.79 TB/s |
| 消費電力 | 300W | 300W |
| 浮動小数点性能 | 91.06 TFLOPS | 110.1 TFLOPS |
| ROPs | 192 | 192 |
| Tensor Cores | 568 | 752 |
画像生成における推論速度を比較
最適化により、画像生成のように複数の重い処理を連続して行うタスクで特に効果を発揮。
Blackwell世代のGPUは、AI推論における新たな基準を確立し、
より高速で効率的な処理を実現しました。
Transformerを中心に大幅なレイテンシ削減が見られ、実用上の体感速度にも大きく貢献しています。
また、FP4だけでなく、FP16・BF16・FP8といった他の精度設定でも、全体として約1.7倍前後の高速化が確認されました。
TensorRT 10.0以降では、Blackwell世代以降のGPUでFP4という軽量な演算精度が行列演算で正式にサポートされており、これが
推論処理全体の高速化につながっています。96 GBのGDDR7メモリと1.8 TB/sのメモリ帯域により、大規模な生成AIモデルでも
安定して高速な処理が可能です。
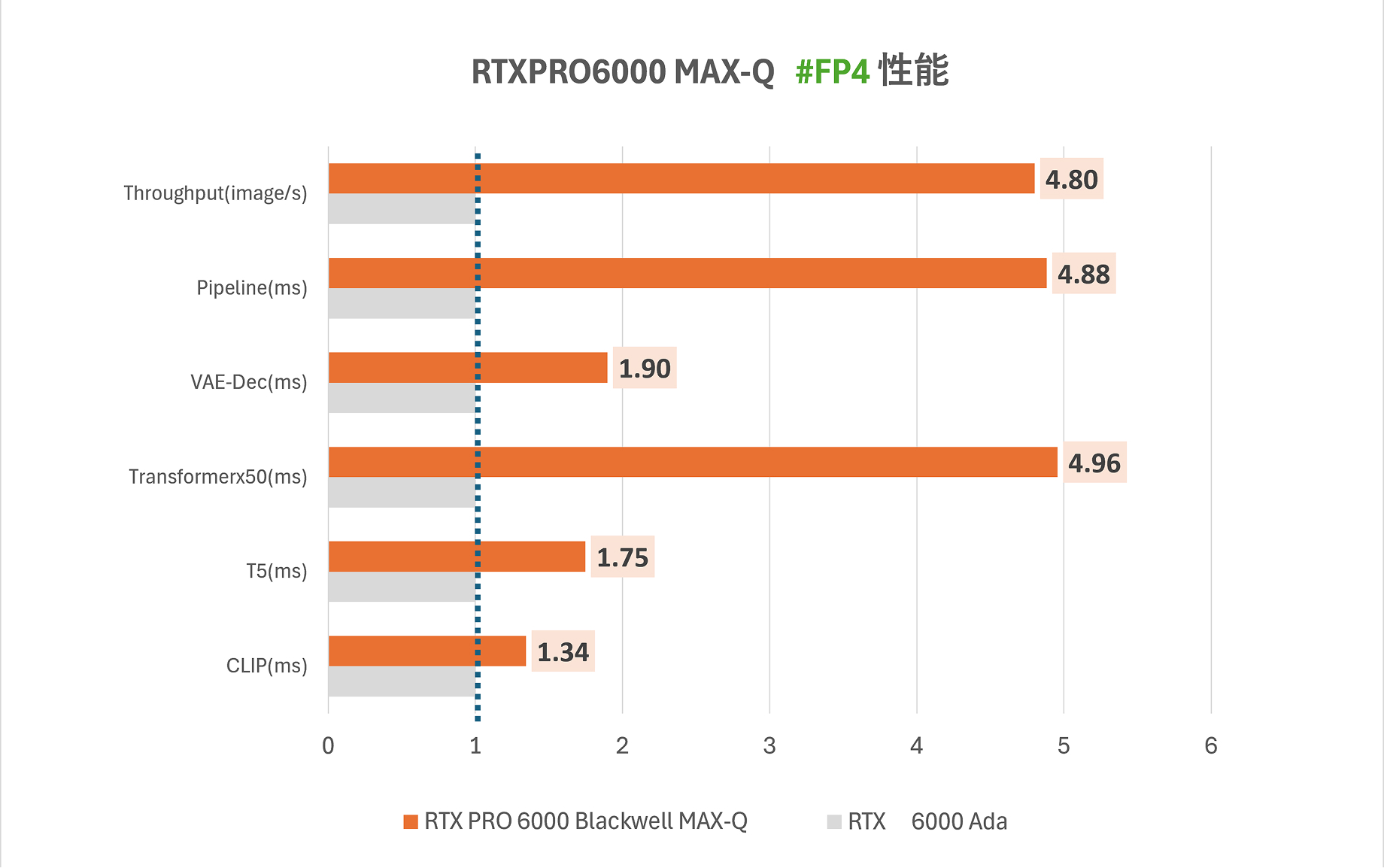
各種数値・表記の補足
※1 CLIP(ms)
入力されたテキストを画像生成用のベクトルに変換する前処理時間
※2 T5(ms)
プロンプトの補完・修正に使われる言語モデル処理時間
※3 Transformerx50(ms)
画像の潜在表現を生成する処理時間
※4 VAE-Dec(ms)
潜在ベクトルを画像に復元するデコード処理時間
※5 Throughput(image/s)
1秒間に何枚画像を出力できるかの指標
Pipeline(ms)
※1~5 すべてを合計した画像生成全体の処理時間
SPECIFICATION
DeepLearningSTATIONII
製品仕様
- CPU
-
Intel Socket LGA4677
インテル Xeon W-3500シリーズ - GPU
-
NVIDIA RTXシリーズ
NVIDIA RTXシリーズ(最大4基)
NVIDIA RTX PROシリーズ(型番により1基もしくは4基)
NVIDIA GeForce 5090 32GB GDDR7(最大1基) - マザーボード
- Intel W790 Chipset
- メモリ
-
8スロット
8 x DIMM, Max. 512GB, DDR5-4800 MHz ECC Register Memory - BootDevice
- M.2 NVMe SSD 960GB ~ 3.84TB
- HDD
- SATAⅢ 4TB ~ 20TB
- SSD
- SATAⅢ 960GB ~ 7.68TB
U.2 960GB ~ 7.68T - RAID
- ソフトウェアRAID (オプション)
- ネットワーク
-
2 x Intel 10Gb Ethernet
1 x Realtek 1Gb (IPMI) - I/Oポート
-
Back Panel
1 x USB 3.2 Gen 2x2 port(s) (1 x USB Type-C)
5 x USB 3.2 Gen 2 port(s) (4 x Type-A + 1 x USB Type-C)
2 x USB 2.0 port(s) (2 x Type-A)
1 x VGA port (D-Sub)
2 x Intel 10Gb Ethernet ports
1 x Realtek 1Gb Ethernet port
5 x Audio jacks
1 x Optical S/PDIF out port
1 x BIOS FlashBack™ button
1 x Clear CMOS buttonFront
2 x USB 3.2 Gen 1 port(s) (1 x Type-C, 1 x Type-A) - 拡張スロット
-
PCIe Gen 5.0 x16 slots
Xeon W3400搭載時: 7 x PCIe 5.0 slot(s) (x16/x16/x16/x16/x16/x16/x16)
Xeon W2400搭載時: 4 x PCIe 5.0 slot(s) (x16/x16/x16/x16) - ケース
-
DeepLearningSTATIONII ジーデップオリジナルケース 黒(W290 x D515 x H439mm) ※ラックマウントレール
別売り - 電源
-
2 x 100V入力 1200W PLATINUM以上認証電源(GPUワークステーション用)
2 x 200V入力 2000W PLATINUM以上認証電源(GPUワークステーション用)
*システム構成により変更となる場合がございます。
- 保守契約
-
標準 : 1年間センドバック方式
オプション : 3年間センドバック方式 - サイズ
- (W)290 x (H)452 x (D)515 mm
- 重量
- 約28kg〜
※システム構成により変わります
CASE STUDIES
導入事例
ジーデップ・アドバンスの製品を導入いただいたお客様の実例を多数ご紹介。
各業界の課題解決や業務効率化、新たな価値創出にどのように貢献したのか、具体的な導入背景から効果までを詳しく掲載しています。

京都大学大学院 情報学研究科 様
独自の理論である「記号創発システム」を提唱し、「人間の知能」を理解するために日々試行錯誤を続けている京都大学の谷口忠大教授。幅広い研究を進めるなかで、膨大な計算やシミュレーションの強い味方となっているのが「DeepLearningSTATION II」

大阪大学様
環境デザインに先進のICTを掛け合わせ、社会が抱えるさまざま課題の解決や新たな付加価値の創造に挑んでいる大阪大学の福田知弘教授。そのための研究やシステム開発を縁の下で支えているのが「AIワークステーション」

Spakona様
コンサル業務とシステム開発を両立し、最適な業務効率化の実現をサポートするSpakona。スピーディーなシステム開発とクオリティアップを「DeepLearningBOXⅢ」が後押しする。

富士ソフト様
システムインテグレーターとAI開発の実績を組み合わせ、「AIインテグレーター」ビジネスを加速する富士ソフト。驚異的な計算能力と使い勝手の良さを併せ持つ「NVIDIA DGX-2」がビジネススピーディに応じたAIシステムの提案・導入を後押しする。

海洋研究開発機構 付加価値情報創生部門 様
海洋研究開発機構の松岡氏と日髙氏は、世界レベルで深刻な問題となっている海洋ゴミの研究に挑んでいる。この研究で重要なポイントとなるのが、GPUを利用したAIの学習と画像解析。最新アーキテクチャの高性能GPUを搭載する「DeepLearning BOX/Alpha」が、これらの作業を強力にバックアップする。

EmbodyMe様
AIによって革新的な映像サービスを生み出すEmbodyMeは、映像の未来を切り開くためにチャレンジし続けるスタートアップ。優れた性能と柔軟性を兼ね備えた「NVIDIA DGX A100」が、AIの進化を支えることでエンジニアの研究をさらに加速させる。

武蔵精密工業様
AI/ディープラーニングの活用が企業の成長のカギを握るといわれる中、実際に取り組むとなると二の足を踏んでしまう企業も少なくない。ここでは、製造現場における要員比率の4割を占めていた搬送工程と検査工程にAIを導入した武蔵精密工業の事例を紹介。この成功事例が、AI/ディープラーニングを推進したい企業の強い後押しになることだろう。
Infervision.Japan様
ディープラーニングによる画像分析技術を医療に活用し、世界中の医師をサポートするInfervision。AI診断支援ソフトウェアが、コロナ禍にある日本の医師を強力に支援する。

セキュリティイニシアティブ様
ペンテストに基づいて幅広いセキュリティのアドバイスを行うセキュリティイニシアティブ。超高速処理を可能にする「DGX A100」が、企業とペンテスターを強力にサポートする。

明星大学 情報学部 情報学科 並列分散システム研究室様
明星大学の和田康孝先生は、長年にわたって並列処理によるコンピュータシステムの効率化に挑んでいる。これまでとはひと味違う手法でシステムの効率化を実現しようとしている和田氏にとって、FPGAボード「Alveo U50」は新たな可能性の扉を開く重要なカギだ。