


search製品名・スペックから検索







FPGAボード「Alveo U50」が システムの新たな効率化を実現
明星大学 情報学部 情報学科 並列分散システム研究室様
明星大学の和田康孝先生は、長年にわたって並列処理によるコンピュータシステムの効率化に挑んでいる。これまでとはひと味違う手法でシステムの効率化を実現しようとしている和田氏にとって、FPGAボード「Alveo U50」は新たな可能性の扉を開く重要なカギだ。

明星大学は、東京都日野市のワンキャンパスに計9学部12学科を設置する私立の総合大学。「自己実現を目指し、社会貢献ができる人の育成」を教育目標に掲げ、学びあいを通して学生たちの「学び続ける力」や「協働する知性」を育んでいる。

明星大学 情報学部 情報学科 和田康孝先生
情報学部 情報学科の和田康孝先生は、並列処理技術を軸とする研究を学生時代から長年手掛けており、現在は「高性能」「低消費電力」かつ「使いやすい」という特徴を持ったコンピュータシステムの実現を目指している。研究の主眼は「さまざまな要素を組み合わせてシステムを効率化させる」ことにあり、「プログラムの実行性能を上げたり、消費電力を下げたり、プログラム自体を作りやすくしたりすることが目的。ひと言で表現するなら、すべての意味で“効率が良い”に行き着く」と和田氏は説明する。
例えば、10個のアプリケーションがそれぞれ別々のプロセッサーで10個同時に動いている場合、システム全体としては「スループットが高い(=効率的に処理している)」という見方ができる。一方で、1つのアプリケーションが1つのプロセッサーでしか動いておらず、残り9個のプロセッサーが止まっている状態では、とても「効率的」とは言えない。
そこで「1つのアプリケーション内にある逐次プログラムを、複数のプロセッサーへ自動的に振り分けるような並列プログラムに変換する仕組みを作る」(和田氏)というのが、シンプルな取り組み例の1つとなる。これに加えて、変換された並列プログラムをより高速に実行するようなコンピュータアーキテクチャや、プログラムの実行性能を保ったままシステムの消費電力を低減するような仕組みなども研究している。
複数のシンプルネットワークで高速化をはかる新たな手法
現在の和田氏の研究において、大きな役割を果たしているものの1つに「FPGA」がある。FPGAは「Field-Programmable GateArray」の略で、端的に表現すると「現場でのプログラムが可能な集積回路」となるだろうか。集積回路なので当然ハードウェアだが、その名の通り“内部の回路構成を自由にプログラミングできる”ことから、ソフトウェアのような性質も兼ね備えているのが大きな特徴となる。このFPGAを利用し、和田氏が取り組んでいるのが「シンプルなニューラルネットワークを複数並列に用いた、高速・高精度な深層学習処理に関する研究」である。
そもそも深層学習では、豊富なデータを使った学習によって「ニューラルネットワークの構造を大きく深く、そして複雑にすることで認識能力を高める」というのが、一般的な方向性の1つとしてある。しかし、この方向性では「学習に時間がかかる」とともに、巨大で複雑になったニューラルネットワークの性能を高めるためには、「ニューラルネットワークの不要な結合を切断したり、使用していないニューロンを削除したりするといったチューニングが必要になる」(和田氏)という課題があった。さらに、そこまでチューニングしてニューラルネットワークの性能を上げたとしても、システムを少しでも変更すると「また1からチューニングや学習をやり直す必要がある」という点もデメリットと言えるだろう。
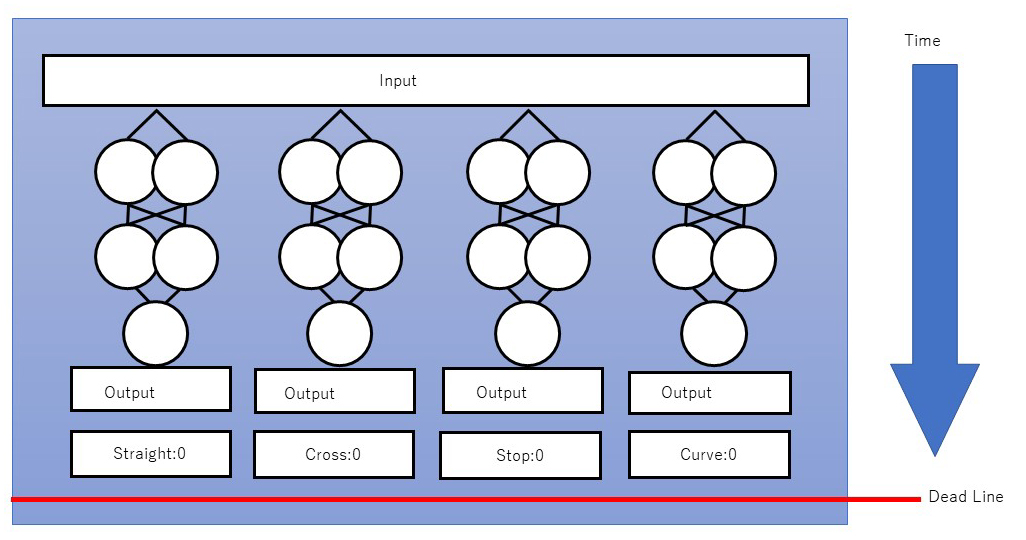
FPGAは複数のシンプルなネットワークを用いた並列推論によって性能を向上させる
そこで和田氏が考えたのは、FPGAを活用して「シンプルなニューラルネットワーク 構造を複数組み合わせることで、システム全体の高速化をはかる」という手法である。
例えば、自動運転を想定した画像認識の場合、従来の深層学習では1つの巨大で複雑なニューラルネットワークによって自動車や歩行者、道路、建物、動物などのすべてを認識させようとしてきた。しかし、FPGAを活用した和田氏の手法では「複数のシンプルなニューラルネットワークを用意し、Aのニューラルネットワークは自動車、Bは人間、Cは道路といった感じで、認識する対象をそれぞれに振り分けて処理を簡略化。これにより、ニューラルネットワーク全体の構造を小さくして高速化を実現する」(和田氏)。
この研究の一環として、和田氏の研究室では、組み込みタイプの小型FPGAボードを搭載した模型自動車による自動運転のコンテスト「相磯秀夫杯 FPGAデザインコンテスト」に学生が出場。その成果やさらなる可能性を追求している。
動的に回路構成を書き換えて効率や利便性を上げる
また、FPGAは基本的に複数の回路が並列に並んでいるため、和田氏は「データ入力から認識、結果出力までの時間を短くできる」や「認識対象を増やしたい場合、新たに回路を追加してそこだけを学習させれば簡単に追加できる」といった点もメリットとして挙げる。このようなメリットを踏まえた取り組みとなるのが、大川情報通信基金の研究助成を受けて進めている「自己進化する推論システムのFPGAを用いた試作検討」である。
この研究では、システム自身が何らかの方法で現状を把握し、その状況に応じて「自動でFPGAの回路構成を書き換え、回路を柔軟に増やしたり減らしたりすることで、効率や利便性を上げる」という仕組みを想定。システム自体が「自分自身で適応的に中身を変えていくようなことができると面白い」と和田氏は考えている。ただし、このシステムを汎用的に適合させることは「まだまだ難しい」ことから、現時点では「画像認識のアプリケーションを対象とした仕組みの構築」を目指しているそうだ。
Xilinx社のFPGAボードで新たな研究にチャレンジ

研究室に導入したFPGAボード「Alveo U50」を搭載するマシン
この「自己進化する推論システムのFPGAを用いた試作検討」などを加速させるべく、和田氏は2021年2月、Xilinx社のFPGAボード「Alveo U50」を研究室に導入した。Alveo U50は、自動運転のコンテストで使用したFPGAボードよりも規模の大きい回路に対応できるとともに、OpenCLやC言語が使えることから「高位合成と非常に相性がいい」(和田氏)とのこと。そういった点を上手く活用できれば、「より規模の大きい回路を動かしながら、不要になった回路があれば柔軟に入れ替え、状況に応じた機能を自由に取捨選択できるような仕組みを構築できる」と考え、和田氏は試行錯誤を続けている。
「深層学習やニューラルネットワークの研究では、CPUやGPUがよく利用されていますが、私が取り組んでいる研究にはFPGAが 最適だと感じています。実際、CPUやGPUは内部のアーキテクチャをユーザーやソフトウェアから変更できないので、私の研究には不向きです。また、FPGAはハードウェアでありながらソフトウェア的な特性も持っています。ソフトウェアだけで対応しなければならないときの効率の悪さを、ハードウェアの特性で補えるのも魅力です」(和田氏)
これに加えて、和田氏はAlveo U50の上位モデルとなる「Alveo U200」も、2020年11月に学内用として導入した。こちらは、他の大学と共同で進めている「Approximate Computingによるシステムの高効率化に関する研究開発」に利用している。通常、コンピュータは「処理性能を上げると消費電力も基本的に上がる」ものだが、Approximate Computingは「計算の正確さと、処理性能あるいは消費電力のトレードオフを最適化する」ために用いられる技術。具体的には、処理全体に対してある程度の計算間違いを一律に許容することで、全体的な消費電力の抑制や計算時間の短縮を実現するものである。
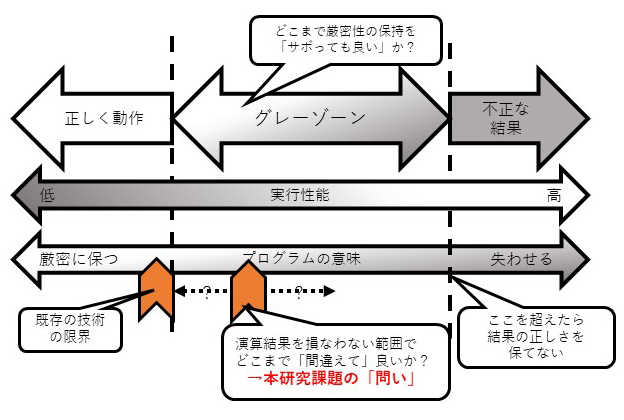
Approximate Computingによるシステムの高効率化
しかし、この研究で目指しているのは従来のApproximate Computingとはやや異なり、もっと柔軟性を兼ね備えたものを想定。処理全体に対して一律に間違えを許容するのではなく、「間違っても影響が小さい部分を事前に判別できるようなフレームワークを開発し、その部分のみにApproximate Computingの効果を適用する」(和田氏)という仕組みの開発にチャレンジしている。
目指すシステムの実現にあたって重要となるのは「ソフトウェア」
さまざまな研究に取り組むことで「システムの効率化」を突き詰めている和田氏。FPGAを使った仕組みは、利用できるシーンや環境がまだ限定的なことから、将来的には「もう少し汎用的に使えるような仕組みを生み出したい」と考える。その実現のために重要となるのが、ハードウェアの利便性を高める「ソフトウェア」である。
例えば、GPUの爆発的な普及の背景には「CUDA」が大きく関わっており、「歴史を振り返れば、まずはハードウェアのブレイクスルーがあり、それに後追いする形でソフトウェアがキャッチアップして普及していくという流れが繰り返されている」(和田氏)。それだけに、FPGAもハードとソフトの両方が上手くかみ合わさっていけば、これまで以上に飛躍する可能性は高いだろう。
「FPGAが普及するのはもちろん歓迎です。ただ、個人的には『より良く使えるようなシステムとして、ソフトウェアとハードウェアが連携できるようになって欲しい』という思いはあります。そうすれば、私の研究ももっと範囲を広げていくことが可能になるはずです」(和田氏)
![]()
明星大学 情報学部 情報学科 並列分散システム研究室様の使用モデル

Alveo U50
機械学習をはじめとするさまざまなワークロードに対応し、最適化されたアクセラレーション機能を提供するロープロファイル型のデータセンターアクセラレータカード。TDP 75Wと電力効率に優れるほか、100Gbps ネットワークI/O、PCIe Gen4、HBMを統合し、あらゆるサーバー形態で運用できる。


