


search製品名・スペックから検索







GTC2022 秋 基調講演レポート 特別寄稿 笠原一輝

NVIDIAが発表したGeForce RTX 40シリーズ(出典:NVIDIA)
NVIDIAは、9月19日(米国時間)から開催したGTCにおいて、同社の最新GPUアーキテクチャとなる「Ada Lovelace」(エイダ・ラブレス、英語の発音はアイダ・ラブレースの方が近い)を発表し、それに基づいた製品としてコンシューマ向けのGeForce RTX 40シリーズを発表したほか、ワークステーション用のNVIDIA RTX 6000、データセンター向けのNVIDIA L40 GPUなどのリリース予定が発表された。ここでは、GTCで明らかにされたAda Lovelaceアーキテクチャのハイレベルの強化点を紹介していきたい。
また、GTCに先だって、NVIDIAは同社が「Grace」の開発コードネームで開発しているHPC向けのArm CPUの詳細を明らかにしている。それらの詳細に関しても、あわせて紹介していきたい。
-
TSMC 4Nを採用したことで内部演算器が71%増加、電力効率は2倍に、性能は4倍に

Ada Lovelaceアーキテクチャを採用したGPUダイのイメージ図(出典:GAMING TECHNOLOGY, ARCHITECTURE AND PRODUCTS、NVIDIA)
-
今回のGTCで発表されたAda Lovelaceアーキテクチャは、2018年に発表されたTuring(チューリング)、2020年に投入されたAmpere(アンペア)に続く同社がRTXと呼んでいるハードウエア・レイトレーシングのエンジン(RTコア)を内蔵したGPUアーキテクチャの第3世代となる。
なお、NVIDIA GPUの開発コードネームは過去の科学者の名前に基づいており、今回のAda Lovelaceも、世界初のコンピュータプログラマーとして知られる19世紀のイギリスの数学者の名前が元になっている。
それぞれのハイレベルの仕様を表にすると以下のようになる。
-
表1 Turing、Ampere、Ada Lovelaceそれぞれのスペック、いずれもアーキテクチャ上の最高構成で、実際の製品化に当たってはいくつかの演算器が削られたりしている。例えば、GeForce RTX 4090はGPCが1つ削られて11個になっているなど。GPUアーキテクチャ名 Turing Ampere Ada Lovelace 最大構成ダイ TU102 GA102 AD102 最上位製品 GeForce TITAN RTX GeForce RTX 3090 Ti GeForce RTX 4090 GPC/GPU 6 7 12 TPC/GPU 36 42 72 SM/GPU 72 84 144 CUDAコア/SM 64 128 128 CUDAコア/GPU 4608 10752 18432 RTコア/GPC 72(第1世代) 84(第2世代) 144(第3世代) Tensorコア/GPC 576(第2世代) 336(第3世代) 575(第4世代) L1キャッシュ/SM 96KB 128KB 128KB L2キャッシュ 5.5MB 6MB 96MB メモリ 384ビット/GDDR6 384ビット/GDDR6X 384ビット/GDDR6X メモリ帯域幅 672GB/秒 1008GB/秒 1008GB/秒 TGP 280W 450W 450W トランジスタ数 186億 280億 760億 ダイサイズ 754平方mm 628.4平方mm 608.5平方mm プロセスノード TSMC 12nm FFN サムスン8N TSMC 4N -
Ada Lovelaceの最大の特徴は、NVIDIAがGPC、TPC、SM、CUDAコアと呼んでいる演算器がいずれも増えていることだ。Turing世代以降、NVIDIAのGPUは小さい方からCUDAコア、そのCUDAコアが複数まとめてSM、SMをまとめたのがTPC、TPCをまとめたのがGPCというクラスター構造になっており、そのGPC単位で演算器を増減(スケーリング)させることで、ローエンド、ミッドレンジ、ハイエンドと異なるセグメント向けの製品に展開する製品戦略をとっている。
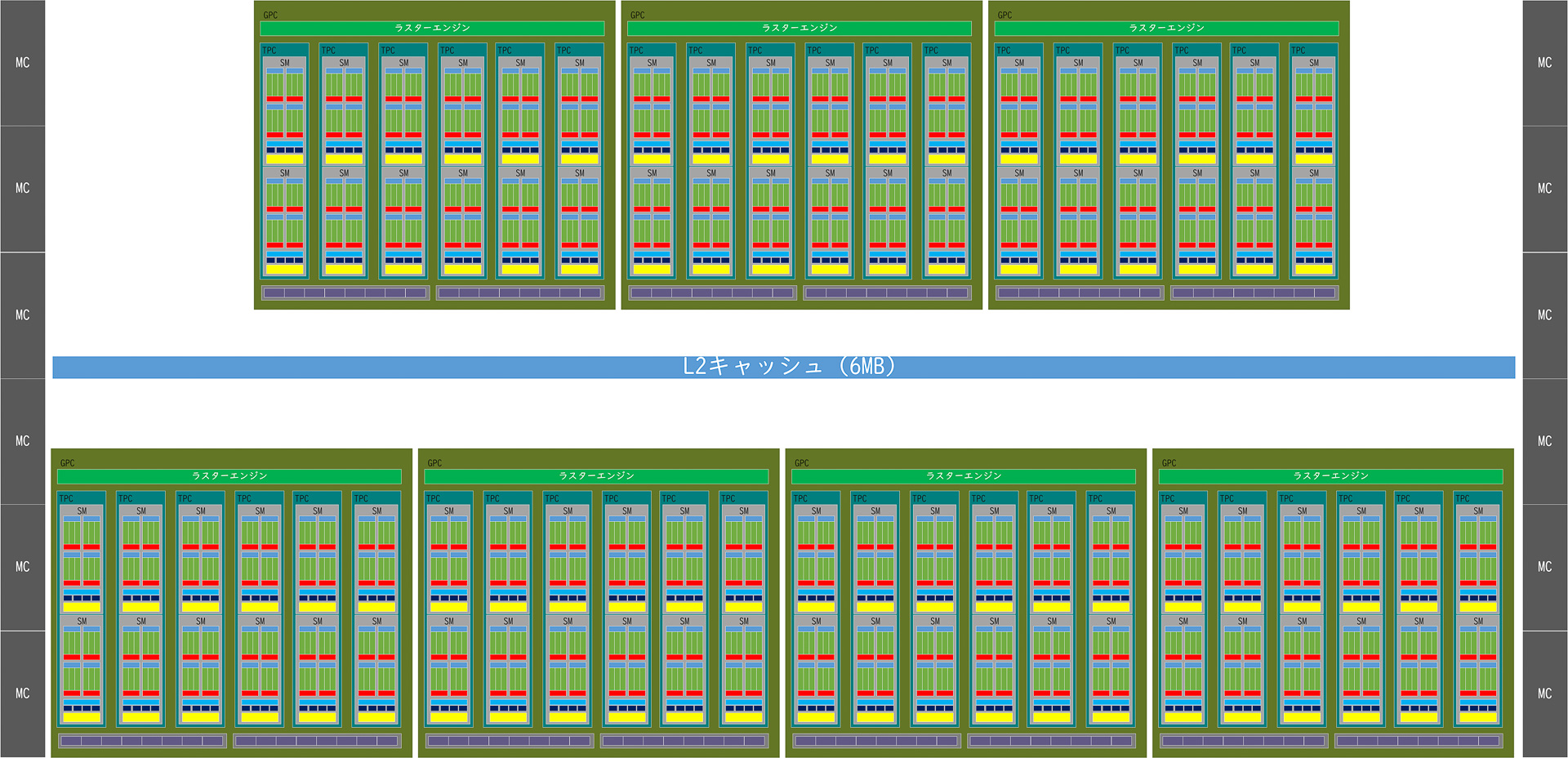
従来のAmpere世代の最大構成(GA102/GeForce RTX 3090 Ti)のブロック図(筆者作成)
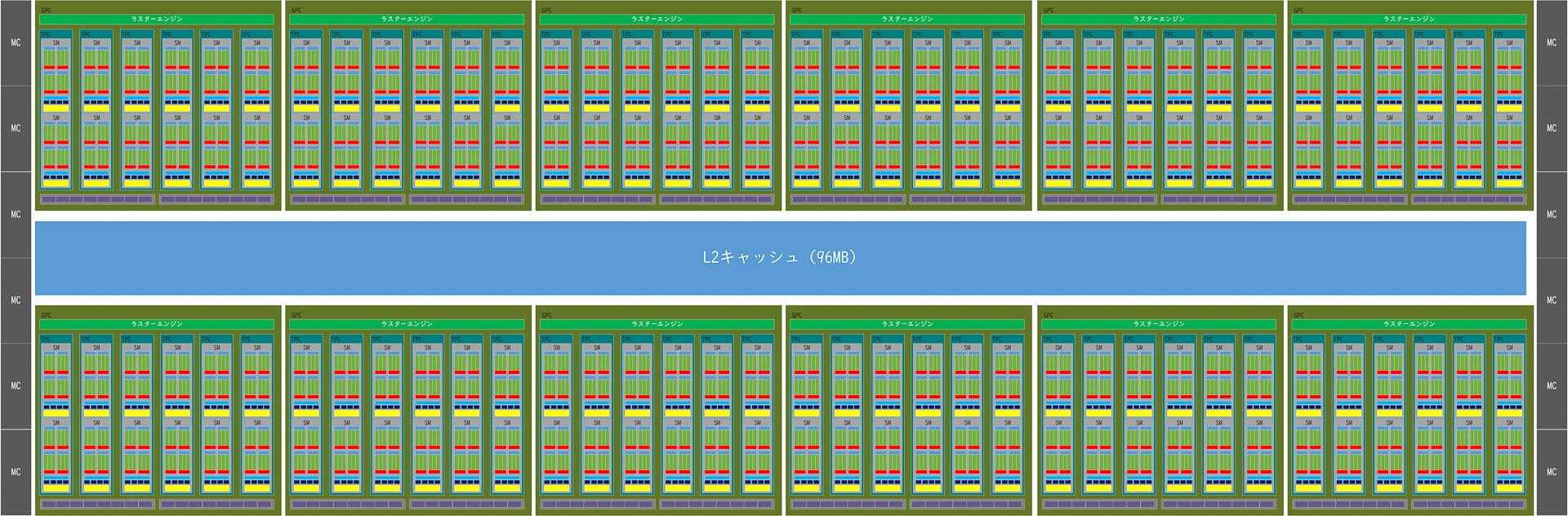
Ada Lovelace世代の最大構成のブロック図(筆者作成-
NVIDIAはAmpere世代のGPUでは、1つのSMに128個のCUDAコア、4つのTensorコア、1つのRTコア、そのSMが2つでTPC、TCPが6つでGPCというクラスター構造をとっていたが、その基本的な構造はAda Lovelaceにも引き継がされている。
Ampereとの最大の違いはGPCの最大数で、AmpereではGPCが最大7基だったのに対して、Ada Lovelaceでは最大12基に増加している。Turing世代に比べると倍、Ampere世代に比較すると71%も増えていることになる。これにより、それに比例してTPCも、SMも、CUDAコアも71%増加しており、それにより大きな性能向上を期待することができる。
また、L2キャッシュの容量が大幅に増やされているのがもう1つの特徴で、Turing世代の5.5MB、Ampere世代の6MBと比較して10倍以上となる96MBに一気に増やされている(ただし、これはアーキテクチャ上の上限、実際の製品では最上位製品のGeForce RTX 4090でも76MBというスペックになっている、これは製造時の歩留まりなどを考慮しているためだと考えられる)。L2キャッシュは、Ampere世代に比べると16倍の容量になっており、キャッシュにヒットすればメモリレイテンシを大幅に削減することが可能になる。
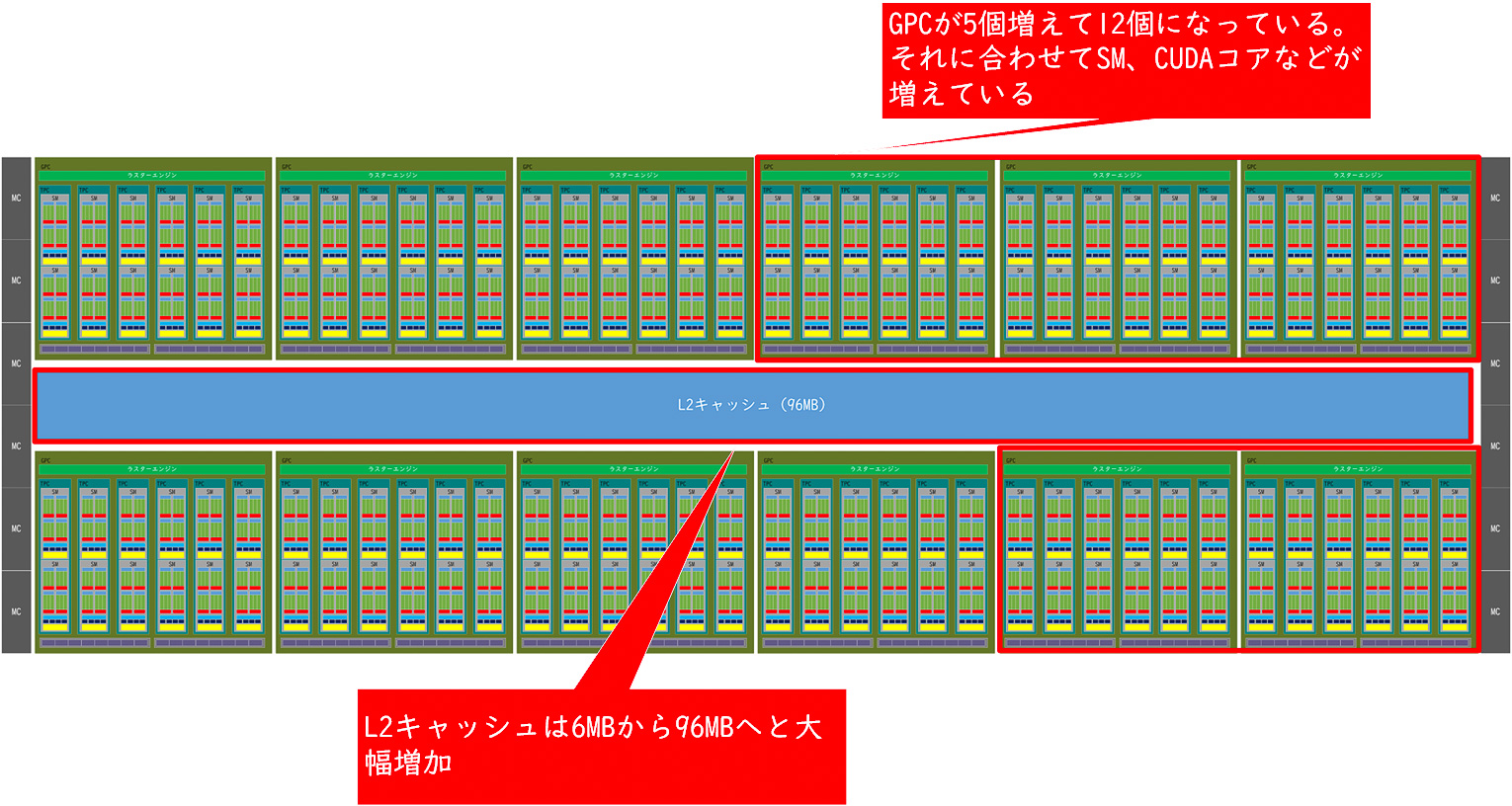
Ampere世代からの進化点はGPCが増えていることとL2キャッシュが増加していること
-
そうした演算器の大幅増加やキャッシュメモリの増加を可能にしたのは、プロセスノードと呼ばれる製造技術が微細化したことが大きく影響している。TuringはTSMCの12nm、AmpereはSamsung Electronicsの8N(8nm)という製造技術を利用したファウンダリーの工場で製造されていた。それに対してAda Lovelaceは、現時点で最も進んだプロセスノードと考えられるTSMCの4N(4nm)を利用して製造されており、それによりAmpere(GA102)とほぼ同じようなダイサイズ(600平方mm前後)であるのに対して、トランジスタ数は280億から760億へと増えており、その増えたトランジスタを演算器やキャッシュメモリを増やすことに利用したため、こうした仕様が可能になったと考えることができる。
-
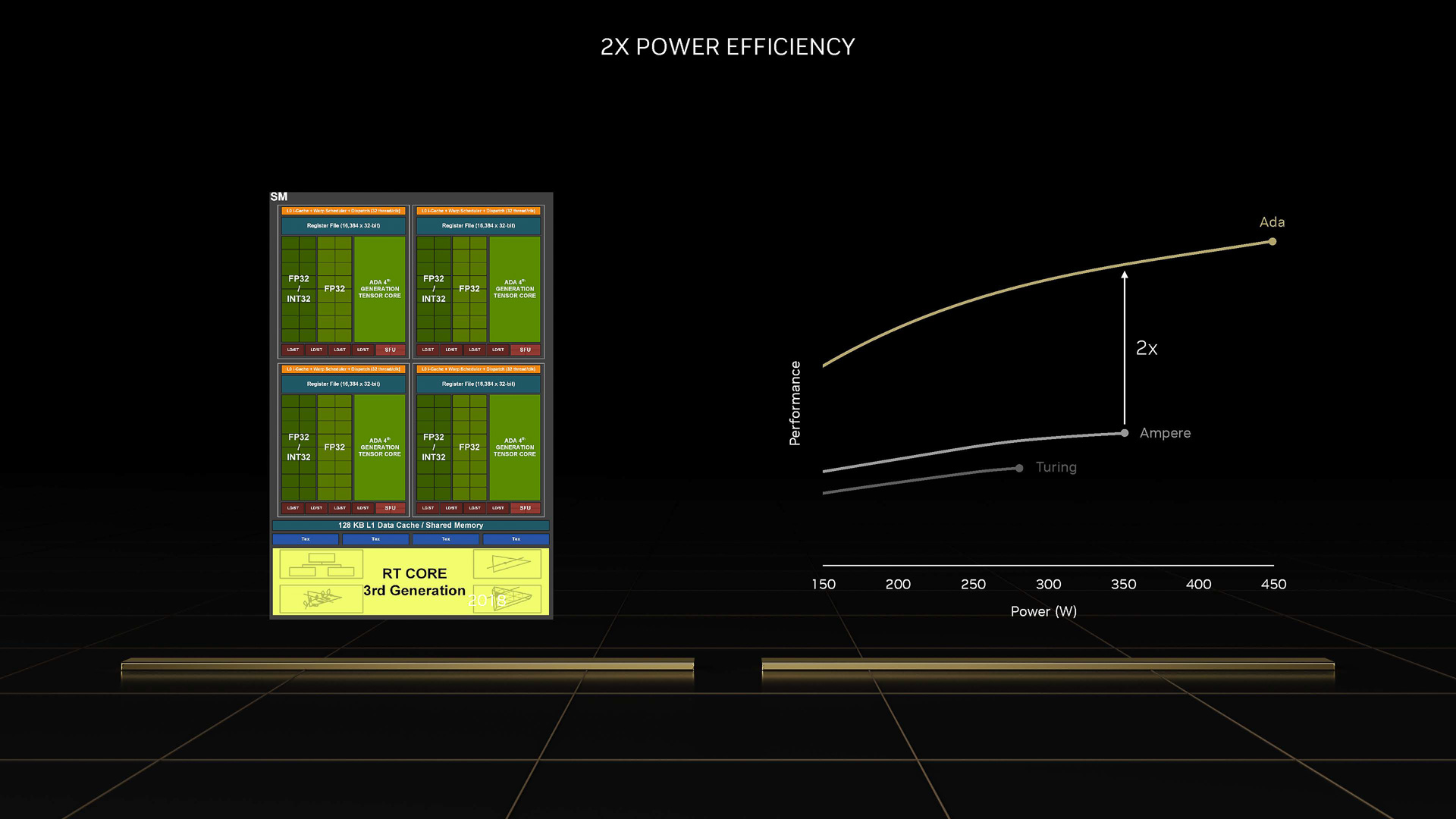
同じ消費電力であれば性能は2倍になり電力効率が2倍になっている(出典:GAMING TECHNOLOGY, ARCHITECTURE AND PRODUCTS、NVIDIA) 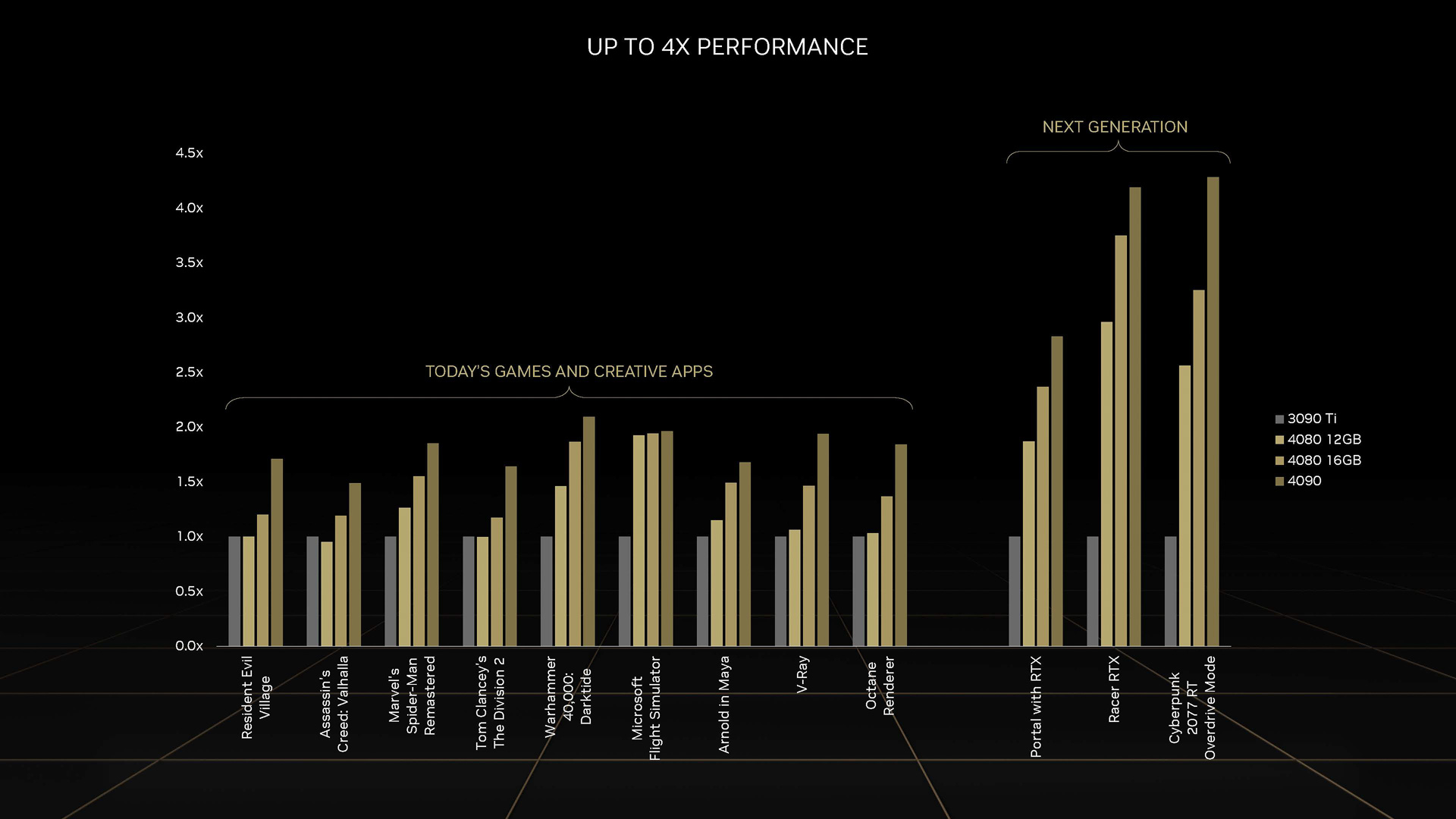
ソフトウエアの最適化が進めば4倍の性能を実現(出典:GAMING TECHNOLOGY, ARCHITECTURE AND PRODUCTS、NVIDIA)
-
NVIDIAによれば、こうした強化により、同じ消費電力では2倍の性能を実現することが可能で、ゲームタイトル側の最適化が行なわれれば4倍の性能が実現されると説明している。
-
RTコアは第3世代に、Tensorコアは第4世代に進化、AV1エンコーダも追加に

RTコアが大きく改良されることで、処理能力が向上する(出典:GAMING TECHNOLOGY, ARCHITECTURE AND PRODUCTS、NVIDIA)
-
RTXシリーズの特徴であるハードウエア・レイトレーシング・エンジンとなる「RTコア」は第3世代に、「Tensorコア」は第4世代へと進化している。そして、GPCが最大12つに増えたことで、RTコア、Tensorコアもそれぞれ増えているのがAda Lovelace世代の特徴と言える。
特にRTコアは大きな進化を遂げており、NVIDIAが「第3世代」と呼ぶエンジンに進化している。NVIDIAによれば、そもそもレイを処理するスループットが2倍になっていること、さらに第3世代のRTコアには、従来のRTコアの機能に加えて、「Opacity Micromap Engine」(不透明度マイクロマップエンジン)と「Displaced Micro-Mesh Engine」(ディスプレイスド・マイクロ-メッシュ・エンジン)という2つの新しいエンジンが実装されていることが強化点となる。
Opacity Micromap Engineはトライアングル(三角形)が不透明、透明、不明かにかかわらずRTコアだけでレイを処理することを可能にする仕組みを提供する。通常、シェーダがトライアングルに透明、不透明などのデータをもっておりトライアングルにレイがあたると、そのたびにシェーダが呼び出されて処理が行なわれることになり、スレッドの処理が長引くなどの性能低下が発生する。そこで、RTコアに内蔵されたOpacity Micromap Engineを利用すると、RTコアだけでその処理をほぼ行なうことが可能になり、必要な場合だけシェーダに返されるので、性能低下を防ぐことができる。
Displaced Micro-Mesh Engineは、複雑になるジオメトリ(幾何学)演算をよりシンプルな構造にすることで、レイトレーシングの処理を軽減するためのエンジン。ゲームなどの表現力があがればあがるほどより増していくジオメトリの複雑性が増していく。そうしたジオメトリな演算が複雑になればなるほどデータ構造も複雑になり、それにより必要となるメモリ量も増えていく。そこで、Displaced Micro-Mesh Engineでは、レイトレーシングの処理を行う時にそうした複雑なデータ構造を、アルゴリズムを利用して複雑化を回避して、シンプルなデータとして処理することが可能になる。
この他にも、処理の順序を入れ替えて同じ処理をまとめて実行することで処理の効率を改善するシェーダ実行リオーダリング(Shader Execution Reordering)、第4世代のTensorコアではFP8を利用したAI推論ができるようになっていること、さらにはフレーム間にAIが作り出した補正フレームを入れることでより高品質なアップスケーリングを行なえるようにしたDLSS3などもAda Lovelace世代の特徴としてあげることができる。
また、Ada Lovelace世代では、エンコーダも強化されている。Ampere世代までは、AV1のデコードはできたが、AV1のエンコードはできなかった。しかし、Ada Lovelaceではエンコードが可能になっており、かつエンコーダはデュアル構成に強化されたため、8K/60fpsないしは4つの4K/60fpsの動画を処理することが可能になっている。

GeForce RTX 40シリーズ(出典:GAMING TECHNOLOGY, ARCHITECTURE AND PRODUCTS、NVIDIA)
-
NVIDIAはこうしたAda Lovelaceの最初の製品として、NVIDIA GeForce RTX 40シリーズを発表し、GeForce RTX 4090、GeForce RTX 4080 16GB、GeForce RTX 4080 12GBの3つの製品を投入する計画を明らかにした。GeForce RTX 4090は10月12日(米国時間に)、GeForce RTX 4080の2製品は11月に発売される予定。それぞれAD102、AD103、AD104というダイ(NVIDIAでは1つのGPUアーキテクチャからGPCを増やしたり減らしたりすることで、製品バリエーションの展開を行なっている)に基づいており、スペックや価格は表2の通りだ。
-
製品名 GeForce RTX 4090 GeForce RTX 4080 16GB GeForce RTX 4080 12GB ダイコードネーム AD102 AD103 AD104 GPC 11 7 5 TPC 64 38 30 SM 128 76 60 CUDAコア 16384 9728 7680 メモリサイズ/種類 24GB/GDDR6X 16GB/GDDR6X 12GB/GDDR6X メモリバス幅/データレート 384ビット/21Gbps 256ビット/22.4Gbps 192ビット/21Gbps メモリ帯域幅 約1TB/秒 716.8GB/秒 504GB/秒 L2キャッシュ 72MB 64MB 48MB トランジスタ数 763億 459億 358億 ダイサイズ 608.5平方mm 378.6平方mm 294.5平方mm TGP 450W 320W 285W 発売予定 10月12日 11月 11月 市場想定価格 1599ドル 1199ドル 899ドル
表2 GeForce RTX 40シリーズのスペック - また、NVIDIAはこの他にも、NVIDIA RTXシリーズ(かつてQuadroのブランド名で呼ばれていたワークステーション向け製品)の製品としてNVIDIA RTX 6000、データセンター向けのNVIDIA Lシリーズ(従来のAmpere世代ではNVIDIA Aシリーズとして展開されていた、データセンター向けGPUの後継製品)のNVIDIA L40をリリースする計画であることを明らかにしている。現時点では両製品共にスペックなどは発表されていないが、いずれも最上位の製品になるため、AD102をダイとして採用する可能性が高く、こちらも今後のアップデートを待ちたいところだ。
-
Arm Neoverse V2ベースの72コアCPUとなるGrace、NVLink-C2Cでスケールアップ

Graceの2チップモジュール。CPUとGPUはNVLink-C2Cで接続され、1モジュールで144コアを実現-
NVIDIAはGTCの開幕前に、開発コードネーム「Grace」(グレース)で知られるArm CPUに関する情報をアップデートしている。
NVIDIAが提供するGraceは、Arm社が提供するCPU IPデザイン「Neoverse V2」に基づいている。Armが提供するNeoverseシリーズは、データセンター向けのArm命令セットを採用したCPUのデザインで、AWSが自社の顧客向けに提供しているGravitonプロセッサなどで採用され、じょじょに採用例が増えている。Neoverse V2はその最新モデルで、開発コードネーム「Demeter」で知られてきたCPU IPデザインになる(Arm社が提供したCPU IPデザインを元に、CPUメーカーが自社製品に実装を行なう)。
NVIDIAのGraceはこのNeoverse V2を、最大72コアを1つのダイに実装している。同時に最大で117MBのL3キャッシュ、またメモリコントローラはHBM2e、DDR5、さらにはLPDDR5xにも対応しており、HBM2eでは最大1.8TB/秒を、LPDDR5xでは最大546GB/秒の帯域幅を実現する。
こうしたGraceの特徴は、NVIDIAが「NVLink-C2C」と呼んでいるCPUとCPU、CPUとGPUを高効率に接続するプロプライエタリなインターコネクトに対応していることだ。NVLinkはDGX-H100やDGX-A100などのNVIDIA自社ブランドのAIコンピュータでGPUとGPUの接続に利用されているものだが、NVLink-C2CはそれをCPUとCPU、CPUとGPUとの接続にも拡張したものになる。CPU同士の接続に利用する場合には、それぞれのメモリやキャッシュに置かれているデータの一貫性を確保する仕組み(メモリコヒーレンシ)が必要になる。NVLink-C2Cは、NVLinkにそうした拡張を加えたもので、CPUとCPU間を900GB/秒の帯域幅で双方向に接続することが可能になる。
-
これはPCI Express Gen 5を利用した場合に比べると帯域幅で7倍、電力効率で約5倍になるとNVIDIAでは説明している。現在CPU業界はそのPCI Express Gen 5を物理層として利用した業界標準規格「CXL」への移行を進めつつあるが、それに比べてもそれだけの差を実現すると考えられるため、このNVLink-C2CがGraceの大きな武器になる可能性が高い。NVIDIAはこのNVLink-C2Cを利用して、GraceとHopper(NVIDIA H100 GPU)を1つのボードに実装した製品や、Grace2つを1つのボードに実装した製品を計画しており、その場合には1つのボードで144コアのArm CPUとして利用することが可能になる。

Armが発表した資料によれば、NVIDIAのGraceは、2023年に登場する、IntelやAMD(図ではTraditional 2023と表記されている)に比べてシングルスレッド(縦軸)でも、マルチスレッド(横軸)でも高性能を実現(出典:Building the Future Infrastructure on Arm、Arm)
-
GraceのCPU IPデザインである「Neoverse V2」を発表したArmによれば、Graceの性能はシングルスレッドにおいても、マルチスレッドにおいても、IntelおよびAMDが2023年にリリースするx86のデータセンター向けCPUを大きく上回る可能性が高いと予測しており、それが現実になれば、現在HPC向けのGPUサーバーで採用されているx86プロセッサがGraceに置きかえられるということも十分現実的になってくるといえ、こちらも正式なリリースとなる2023年に期待したいところだ。
- 笠原一輝
-
- GTC2022 秋 についてのセッションハイライトや日本のコンテンツについては NVIDIA Japan からもニュースが発信されています。ぜひご覧ください。



