


search製品名・スペックから検索







GTC2023 春 基調講演レポート 特別寄稿 笠原一輝
DGX H100の大量生産開始発表と世間で話題の生成AI向けのハードウエアなどが話題の中心となったGTC基調講演
 NVIDIAのAI論向の演リューション。今回のGTCではH100 NVL、L4が表された。生成AIへの注目度が上がり続けていることで、推論もGPUでという動きが強まりつつある。
NVIDIAのAI論向の演リューション。今回のGTCではH100 NVL、L4が表された。生成AIへの注目度が上がり続けていることで、推論もGPUでという動きが強まりつつある。
(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
3月21日(米国時間、日本時間3月22日)からNVIDIAは同社の年次イベントGTC 2023を開催し、その開幕イベントとして同社 CEO ジェンスン・フアン氏による基調講演が行なわれた。NVIDIAのGTCは、ここ数年はオンラインのみのバーチャルイベントとして開催されており、春(3月)と秋(9月)の2回行なわれることが最近恒例となっている。
昨年のGTC 2022(春)では同社の新しいGPUアーキテクチャ「Hopper」を採用したNVIDIA H100 GPUを発表し、それを搭載したAIスーパーコンピューターとして「DGX H100」を発表した。本年のGTC ではそうした新しいGPUは発表されなかったが、出荷が伸び伸びになっていたDGX H100の大量生産開始がアナウンスされ、同時にまもなく出荷開始される予定であることが明らかにされた。
また、今回のGTCでは「ChatGPT」や「Stable Diffusion」などの生成AIと呼ばれる、自然言語処理を利用したチャットボットやAIによる画像生成ツールなどが大きな話題の中心で、NVIDIAも生成AIなどが推論を行なう際に利用できる推論に特化したGPU「NVIDIA H100 NVL」を発表するなど生成AIを実現するソリューションに関しても大きな時間が割かれた。
そうした今回のNVIDIA フアンCEOの基調講演に関して、主にハードウエアの話題を中心に振り返っていきたい。
NVIDIAのフアンCEO、話題の生成AIは「iPhoneモーメント」と表現し、爆発的なAIの普及を予言
 GTC 2023の基調講演で講演するNVIDIA CEO ジェンスン・フアン氏(写真提供:NVIDIA)
GTC 2023の基調講演で講演するNVIDIA CEO ジェンスン・フアン氏(写真提供:NVIDIA)
NVIDIA 共同創始者でCEOのジェンスン・フアン氏は、NVIDIAが3月21日(米国時間、日本時間3月22日)からオンラインで行なったイベント「GTC 2023」の基調講演に登壇し、同社の新戦略や新しい製品に関しての説明を行なった。フアン氏はその基調講演の冒頭で「AIはiPhoneモーメントを迎えている」と述べ、iPhoneが登場してスマートフォンがあっという間に普及していった時期と同じように、これからAIが一般消費者などにも爆発的に普及していく時期を迎えていると強調した。
フアン氏がそういうのも、ここ数カ月の間に「ChatGPT」や「Stable Diffusion」などの生成AIと呼ばれるアプリケーションが、テックメディアのようなテクノロジーを追いかけるメディアだけでなく、テレビや新聞といった一般のメディアでも取り上げられるような状況になっており、世 間の注目を集めているからだ。
例えば、ChatGPTは、OpenAIが開発したGPT(Generative Pre-trained Transformer)と呼ばれる自然言語処理系のAIモデルがベースになっている。GPTはGPT-3、さらにその後継のGPT-4で多くの人が使っても自然に感じるように成熟してきており、そうしたGPTモデル利用したChatGPT、さらにはそれらをベースにしたMicrosoftの「新しいBing」(通称:Bingチャット)などで使われるようになり、一気にブレークした。多くの人が「ググる」(Googleで検索することの俗語)代わりに、ChatGPTに話し言葉で問いかけて答えをもらったり、コンピュータープログラムの作成を指示してコードを書いてもらったりという、新しい使い方を試して話題になっている。
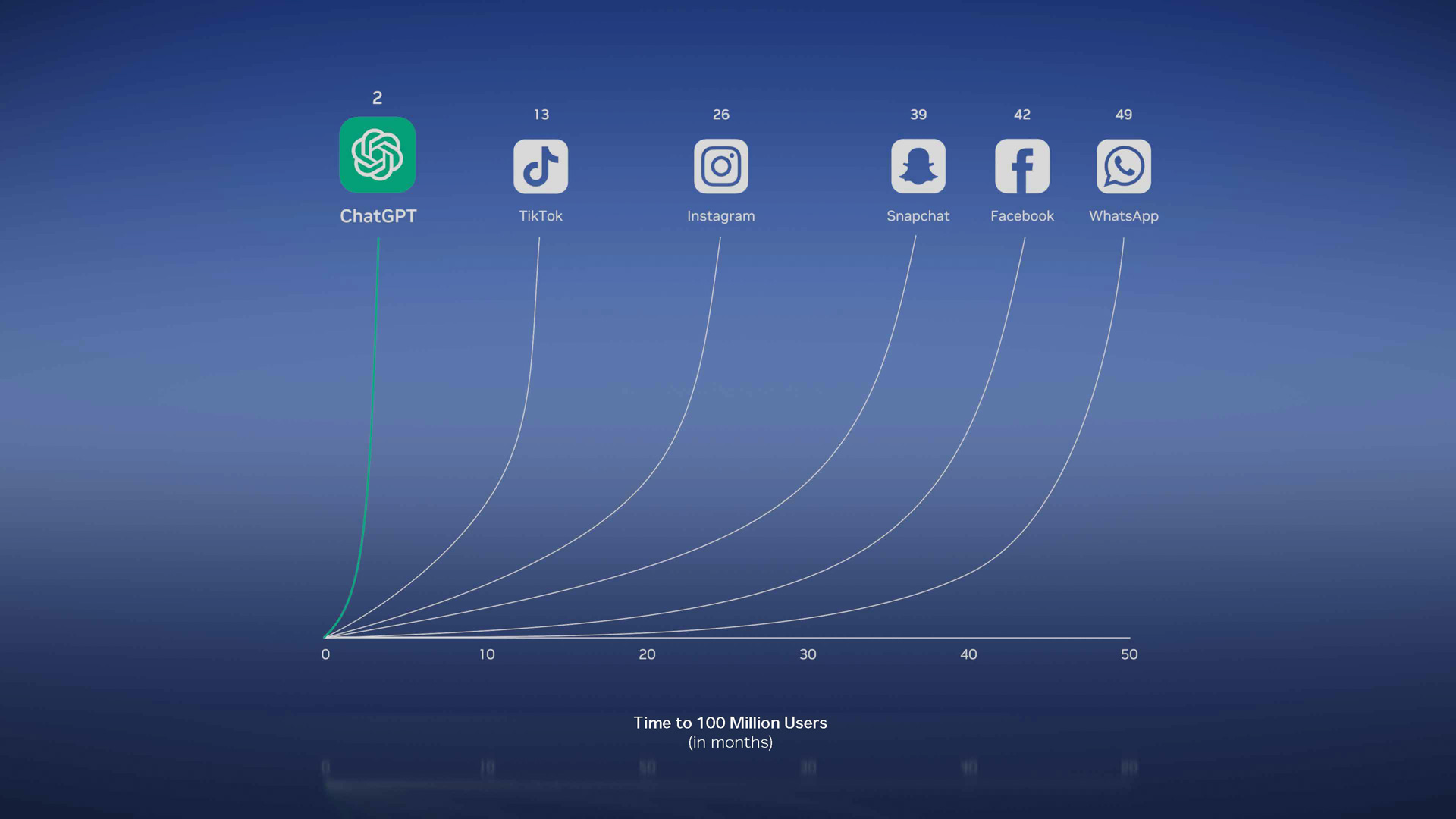 ChatGPTはコンピューーの歴史で最も速く立ちあがったアプリケーション(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
ChatGPTはコンピューーの歴史で最も速く立ちあがったアプリケーション(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
フアン氏は「ChatGPTはコンピューターの歴史の中で最も速く立ち上がったアプリケーションと言ってよい」と述べ、そうした生成AIが急速に立ち上がり、急速に普及しているような状況を「AIはiPhoneモーメントを迎えている」という言葉で表現したのだ。
 NVIDIAは、さまざまな事業領域に向けた開発キット(Acceleration Libraries)を提供し、それを汎用プロセッサとなるCUDA GPU上で動かすというのが今の基本的なビジネスモデル
NVIDIAは、さまざまな事業領域に向けた開発キット(Acceleration Libraries)を提供し、それを汎用プロセッサとなるCUDA GPU上で動かすというのが今の基本的なビジネスモデル
(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
フアン氏はGTC基調講演の冒頭で、さまざまな事業領域(ドメイン)に向けた開発キットを紹介し、NVIDIAのAIソリューションがさまざまな事業領域で利用されていることをアピールした。近年のNVIDIAの基本戦略は、CUDAに対応したGPUという汎用プロセッサに、その上で動作するソフトウエアを開発するための開発キットを、事業領域別に提供していくというもので、GPUとAI向けの開発キット、GPUと自動車向けの開発キット、GPUと医療向けの開発キット、GPUとロボット向けの開発キット…そうした形でいわゆるITだけでなく、自動車、医療、ロボットなどさまざまな産業でAIが活用できるようにしている。そうしたソフトウエア資産が既にたくさんあり、それを利用してさらに開発者がソフトウエアの開発を行なう…そうした好循環がNVIDIAの強みになっている。
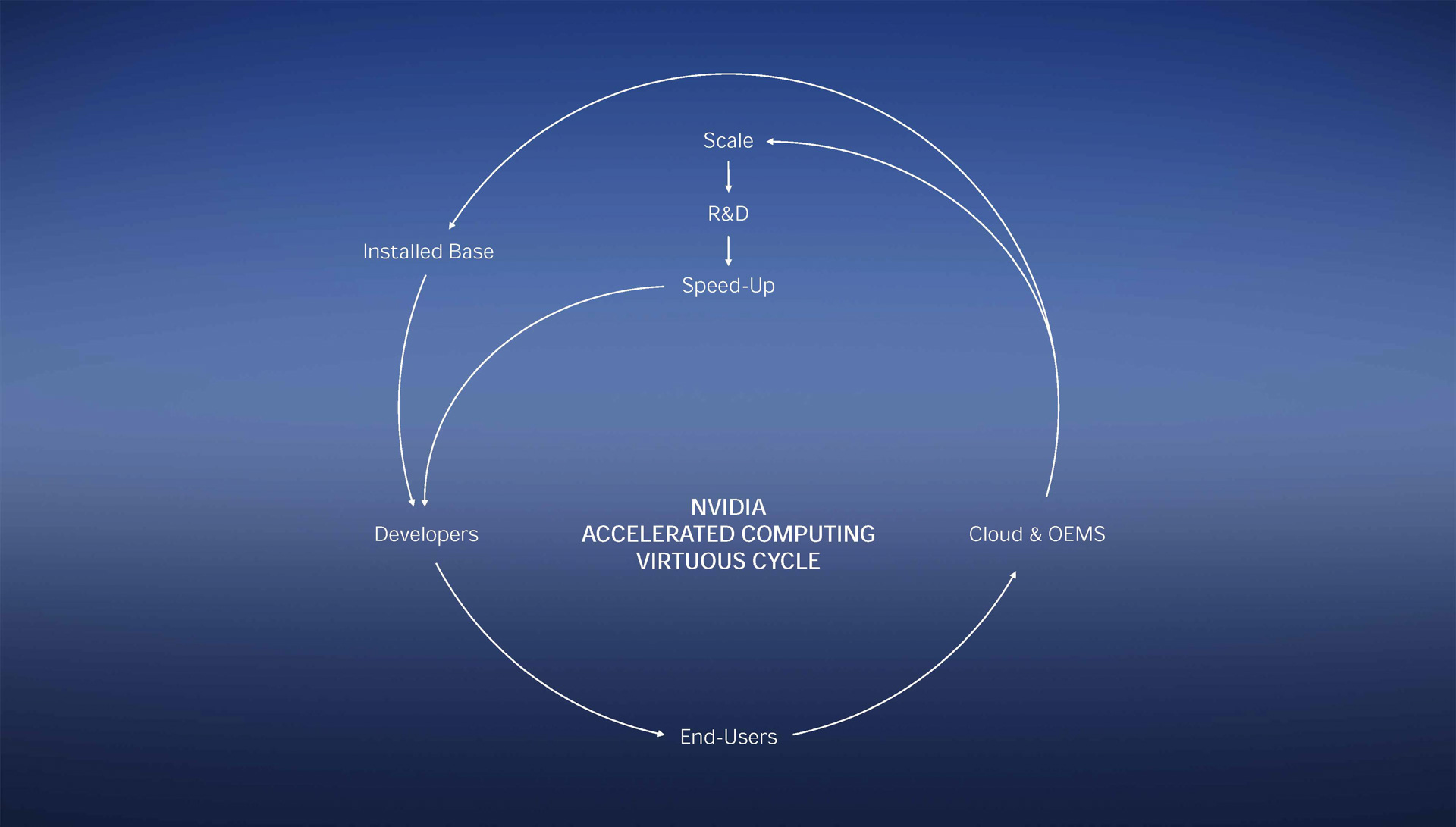 NVIDIAのアクセラレーテッドコンピューティング好循環、こうした好循環がグルグル回っている(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
NVIDIAのアクセラレーテッドコンピューティング好循環、こうした好循環がグルグル回っている(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
フアン氏は「NVIDIA ACCELERATED COMPUTING VIRTUOUS CYCLE」(NVIDIAのアクセラレーテッドコンピューティング好循環)という図を示し、生成AIにより開発者の開発スピードがあがり、それをエンドユーザーが積極的に活用することで、AIの学習や推論に必要となる演算性能があがり、DGX-H100のようなAIスーパーコンピューターのニーズがあがりインストールベースが増えさらに開発者の開発スピードがあがる…そうしたNVIDIAのドメインスペシフィック(特定領域に特化した)開発サイクルが加速していっていると強調した。
-
昨年のGTCで発表されたH100を搭載したDGX H100がついに大量出荷開始、まもなく出荷開始とアナウンス
 NVIDIA DGX H100(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
NVIDIA DGX H100(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
そうしたNVIDIAの事業領域別のソフトウエア開発キット+汎用GPUという戦略を支えるのが、NVIDIAが提供する、多種多彩なGPUのハードウエアだ。NVIDIAはGPUをチップレベル(例えばノートPCや車載システムに搭載される)、PCI Express拡張カードの形状(デスクトップPCやワークステーション、サーバー機器などに搭載される)、さらに近年では8Uのラックマウント形状のケースに八つのGPUでスケールアップされているサーバー機(DGXシリーズ)などさまざまな形状で提供している。そして、DGXではInfiniBand/Ethernetなどに対応しているBlueField-3などのDPUを利用してスケールアウトし、処理能力をラックレベル、データセンターレベルで上げていくこともできるようになっている。フアン氏はそうしたDGXのスケールアップ、スケールアウトを「一つの巨大なGPUのようなものだ」と表現し、それを利用してAI学習時の処理能力を上げ、学習にかかる時間を減らせると強調した。
 DGX H100の内部には八つのNVIDIA H100 GPUが内蔵され、それらを四つのNVLink Switchが接続している(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
DGX H100の内部には八つのNVIDIA H100 GPUが内蔵され、それらを四つのNVLink Switchが接続している(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
 DGX H100の内部構造、八つのGPUを一つのGPUとしてスケールアップして利用できる(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
DGX H100の内部構造、八つのGPUを一つのGPUとしてスケールアップして利用できる(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
 InfiniBandやEthernetでスケールアウトして利用することが可能に(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
InfiniBandやEthernetでスケールアウトして利用することが可能に(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
 ラックレベルで複数のDGX H100をスケールアウトすることで、AIスーパーコンピューターを構築可能に(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
ラックレベルで複数のDGX H100をスケールアウトすることで、AIスーパーコンピューターを構築可能に(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
そうしたDGXの最新製品は、昨年のGTC 2022(春)で発表された「DGX H100」だ。昨年の秋に行なわれたGTC 2022(秋)の段階で、正式な出荷予定は本年の第1四半期であると明らかにされていたが、今回のGTCでは既に大量生産が開始されており、まもなく(英語ではsoon)出荷が開始されるとフアン氏は説明した。
1年前に発表されたDGX H100がここまで正式出荷が伸び伸びになってしまった事情としては、NVIDIAがDGX H100のCPUに採用した「第4世代Intel Xeonスケーラブル・プロセッサー」(以下第4世代Xeon SP)の出荷が1年近く伸び伸びになってしまったという事情が影響していると考えられる。もともと第4世代Xeon SPは昨年の前半には正式に発表される計画だったのだが、結局正式に発表されたのは本年の1月に入ってからで、第4世代Xeon SPをCPUとして採用していたDGX H100もそれにまきこまれる形で出荷が伸び伸びになっていたのだと推測できる。ただ、既にIntelは1月10日(米国時間、日本時間1月11日)に第4世代Xeon SPを正式に発表し、製品の出荷を開始していることをアナウンスしており、まもなくDGX H100の正式出荷も開始されることになるだろう。
そうした意味(他社の製品計画に振り回されることがなくなるという意味)で、フアン氏が今回のGTC基調講演で、同社独自開発のCPUとなる「Grace」に関するさらなる詳細を明らかにできたのは、NVIDIAにとっては大きな進展と言える。
 Graceの性能に関して初めて言及(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
Graceの性能に関して初めて言及(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
NVIDIAが開発しているGraceは、命令セットアーキテクチャにArmv9を採用したArmアーキテクチャのCPUで、CPUのIPデザインとしてはArm社がサーバー向けに提供している「Neoverse V2」をベースにしている。一つのCPUダイに74コアを搭載し、パッケージレベルで二つのダイを一つに統合して144コアのCPUをモジュール形状で提供することを可能にする。また、それぞれのダイに最大で480GBのLPDDR5メモリを接続することが可能で、モジュール全体で960GBのメモリを搭載し、メモリ帯域幅は最大1TB/秒を実現することが可能になる。
フアン氏の基調講演では具体的な性能に関しても言及し、AMDの第4世代EPYCとみられるx86 CPUとの比較で、性能では1.2~1.3倍、電力効率では1.7倍、データセンターのスループットとしては2倍になるというスコアが示された。
このGraceはCPU単体だけでなく、Grace Hopperの開発コードネームで知られるGraceのダイが一つ、Hopper(DGX H100に搭載されているNVIDIA H100 GPU)が一つ搭載されているバージョンも計画されており、将来のDGXではGrace、Grace Hopperが採用されていく可能性が高い。その意味で、NVIDIAのGPUを利用してAI学習環境を整えているユーザーであれば、両製品の今後の動向は要注目と言える。
なお、アーキテクチャ的な詳細などに関してはNVIDIAが公開しているホワイトペーパーなどが詳しいので、興味がある方はそちらも合わせてご参照いただきたい。
Grace Whitepaper https://developer.nvidia.com/blog/nvidia-grace-cpu-superchip-architecture-in-depth/
Grace Hopper Whitepaper https://resources.nvidia.com/en-us-grace-cpu/nvidia-grace-hopper
生成AIで、推論にも注目があつまりつつあり、CPUからGPUへのシフトが起こる
 生成AI向けにはNeMoやPicassoといった開発キットを提供(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
生成AI向けにはNeMoやPicassoといった開発キットを提供(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
今回のGTCでNVIDIAは、推論向けのソリューションにも力を入れていることを大きくアピールした。これまでの推論は、どちらかと言えばCPUで処理されるのが一般的だった。というのも、推論は学習に比較すると軽めの処理と考えられており、GPUによる大量の並列演算を高速に行なうことが必要とされてこなかったからだ。
しかし、ChatGPTやStable Diffusionのような生成AIがその状況を大きく変えつつある。例えば、Stable DiffusionをPCで実行しようとすると、CPU演算した場合には膨大な時間がかかる。このため、Stable Diffusionを多用しているようなユーザーは、GPUの導入を検討して導入することが増えている。同じようなことはデータセンターでも起きており、生成AIを利用したユーザーサービスを提供する事業者がCPUに変えてGPUを、推論処理に利用する例が増えているのだ。
 NVIDIA H100 NVL(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
NVIDIA H100 NVL(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
このため、今回NVIDIAは「NVIDIA H100 NVL」という製品を発表している。このNVIDIA H100 NVLは既に投入されているPCI Express拡張カード形状のH100となる「NVIDIA H100 PCIe」を、「NVLink Bridge」と呼ばれるブリッジモジュールで二つを一つに接続しているという製品になる。最大の特徴は、188GBという1枚のH100 PCIeやH100 SXM(DGX H100に採用されているモジュール)では実現できない大容量のメモリと、メモリ帯域(7.8TB/秒)を実現していることにある。それによりFP32ではH100 SXMと比較して倍の134TFLOPS、Bflot16(Tensor Core)でもH100 SXMと比較して倍の3958TFLOPSを実現していることにある。
| H100 SXM | H100 PCIe | H100 NVL2 | |
| FP64 | 34 teraFLOPS | 26 teraFLOPS | 68 teraFLOPs |
| FP64 Tensor Core | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
| FP32 | 67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
| TF32 Tensor Core | 989 teraFLOPS | 756teraFLOPS | 1,979 teraFLOPs |
| BFLOAT16 Tensor Core | 1,979 teraFLOPS | 1,513 teraFLOPS | 3,958 teraFLOPs |
| FP16 Tensor Core | 1,979 teraFLOPS | 1,513 teraFLOPS | 3,958 teraFLOPs |
| FP8 Tensor Core | 3,958 teraFLOPS | 3,026 teraFLOPS | 7,916 teraFLOPs |
| INT8 Tensor Core | 3,958 TOPS | 3,026 TOPS | 7,916 TOPS |
| GPU memory | 80GB | 80GB | 188GB |
| GPU memory bandwidth | 3.35TB/s | 2TB/s | 7.8TB/s |
| Decoders | 7 NVDEC/7 JPEG | 7 NVDEC/7 JPEG | 14 NVDEC/14 JPEG |
| Max thermal design power (TDP) | 最大700W (可変) | 300-350W (可変) | 2x 350-400W(可変) |
| Multi-Instance GPUs | 7分割/それぞれに10GBメモリ | 7分割/それぞれに10GBメモリ | 14分割/それぞれに12GBメモリ |
| Form factor | SXM | PCIe(デュアルスロット) | 2x PCIe(デュアルスロット) |
| Interconnect | NVLink: 900GB/s、PCIe Gen5: 128GB/s | NVLink: 600GB/s、PCIe Gen5: 128GB/s | NVLink: 600GB/s、PCIe Gen5: 128GB/s |
| NVIDIA AI Enterprise | アドオン | 付属 | アドオン |
表1 NVIDIA H100 SXM(DGX H100に内蔵されているモジュール)、NVIDIA H100 PCIe(PCIeカード1枚)、NVIDIA H100 NVL(PCIeカード2枚)の違い(NVIDIA社の資料より筆者作成)
特に生成AIでは大きなデータを展開することがあり、一般的なGPUのメモリではメモリ容量が足りないことが多くなるのだが、このH100 NVLでは188GBとCPUのメインメモリに匹敵するような大容量のメモリが実現されており、そうした足かせがなくなっていることが生成AIの推論に利用したいユーザーにとっては大きなメリットと言える。
 NVIDIA L4(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
NVIDIA L4(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
また、推論向けだけという訳ではないが、ビデオの処理をデータセンターで行ないたいユーザー向けの製品としてNVIDIA L4も発表されている。このL4はGTC 2022(秋)で発表されたL40のシングルスロット版という位置づけになる。データセンターでコンピュータービジョンの推論や、動画配信などを行なう場合にCPUだけで行なう場合に比べて圧倒的に高い電力効率で処理することが可能になるとNVIDIAでは説明している。
 NVIDIA RTX Ada世代 Laptop GPU(写真提供:NVIDIA)
NVIDIA RTX Ada世代 Laptop GPU(写真提供:NVIDIA)
 NVIDIA RTX 4000 SFF Ada世代(写真提供:NVIDIA)
NVIDIA RTX 4000 SFF Ada世代(写真提供:NVIDIA)
さらに、NVIDIAは昨年の秋のGTCでNVIDIA RTX 6000 Ada世代として発表したAda Lovelaceアーキテクチャのワークステーション向けGPUの追加SKUを発表した。NVIDIA RTX Ada世代というシリーズ名で呼ばれるようになった新しいRTXは、かつて「Quadro」で呼ばれていたワークステーション向けGPUの最新版となる。Ampere世代からQuadroのブランドは廃止され、RTXが新しいブランドになっているのだ。
| NVIDIA RTX 5000 Ada世代 Laptop GPU |
NVIDIA RTX 4000 Ada世代 Laptop GPU |
NVIDIA RTX 3500 Ada世代 Laptop GPU |
NVIDIA RTX 3000 Ada世代 Laptop GPU |
NVIDIA RTX 2000 Ada世代 Laptop GPU |
NVIDIA RTX A1000 6GB Laptop GPU |
NVIDIA RTXA500 Laptop GPU |
|
| アーキテクチャ | Ada Lovelace | Ada Lovelace | Ada Lovelace | Ada Lovelace | Ada Lovelace | Ampere | Ampere |
| CUDAコア | 9728 | 7424 | 5120 | 4608 | 3072 | 2560 | 2048 |
| RTコア | 76 | 58 | 40 | 36 | 24 | 20 | 16 |
| Tensorコア | 304 | 232 | 160 | 144 | 96 | 80 | 64 |
| ピーク単精度性能 (TFLOPS) |
42.6 | 33.6 | 23 | 19.9 | 14.5 | 9.3 | 7 |
| ピークRT Core性能 (TFLOPS) |
98.5 | 77.8 | 53.3 | 46 | 33.5 | 18.2 | 13.7 |
| ピークTensor性能 (TFLOPS) |
681.8 | 538 | 368.6 | 318.6 | 231.6 | 74.6 | 56 |
| GPUメモリ (GDDR6) |
16 GB, ECC4 | 12 GB, ECC4 | 12 GB, ECC4 | 8GB, ECC4 | 8GB | 6GB | 4GB |
| Memoryバス幅 (ビット) |
256 | 192 | 192 | 128 | 128 | 96 | 64 |
| ピークメモリ帯域幅 (GB/s) |
576 | 432 | 432 | 256 | 256 | 168 | 112 |
| TGP | 175 | 175 | 140 | 140 | 140 | 95 | 60 |
| バス | PCI Express 4.0 x16, x8 |
PCI Express 4.0 x16, x8 |
PCI Express 4.0 x16, x8 |
PCI Express 4.0 x8, x4 |
PCI Express 4.0 x8, x4 |
PCI Express 4.0 x8, x4 |
PCI Express 4.0 x8, x4 |
| ディスプレイ | DP 1.4a, HDMI 2.1 |
DP 1.4a, HDMI 2.1 |
DP 1.4a, HDMI 2.1 |
DP 1.4a, HDMI 2.1 |
DP 1.4a, HDMI 2.1 |
DP 1.4a, HDMI 2.1 |
DP 1.4a, HDMI 2.1 |
| NVENC NVDEC6 |
2x (8th Gen) 2x (5th Gen) |
2x (8th Gen) 2x (5th Gen) |
2x (8th Gen) 1x (5th Gen) |
1x (8th Gen) 1x (5th Gen) |
1x (8th Gen) 1x (5th Gen) |
1x (7th Gen) 2x (5th Gen) |
1x (7th Gen) | 1x (5th Gen) |
| NVIDIA Max-Q Technologies5 |
Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| GPUDirect® for Video | 対応 | 対応 | ー | ー | ー | ー | ー |
| HDR7 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 |
| Mosaic5 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 |
| 3D Stereo5 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 |
| Variable rate Shading | 対応 | 対応 | 対応 | 対応 | 対応 | 対応 | ー |
| VR-Ready5 | 対応 | 対応 | 対応 | 対応 | 対応 | 対応(60W+) | ー |
表2 NVIDIA RTX Ada世代 Laptop GPUのスペック(NVIDIA社の資料より筆者作成)
| NVIDIA RTX 4000 SFF ADA世代 GPU | |
| アーキテクチャ | NVIDIA Ada Lovelace Architecture |
| 製造工場 | TSMC |
| プロセスノード | 4 nm NVIDIA カスタムプロセス |
| トランジスター数 | 35.8 billion |
| ダイサイズ | 294.5 mm2 |
| CUDAコア | 6144 |
| Tensorコア | 192 |
| RTコア | 48 |
| 単精度浮動小数点演算性能 | 19.2 TFLOPS |
| RTコア性能 | 44.3 TFLOPS |
| Tensor性能 | 306.8 TFLOPS2 |
| GPUメモリ | 20 GB GDDR6 with ECC |
| メモリバス幅 | 160ビット |
| メモリ帯域幅 | 320 GB/s |
| TGP | 70W |
| バス | PCI Express 4.0 x16 |
| ディスプレイコネクター | mDP 1.4a (4) |
| フォームファクター | 2.7” (H) x 6.6” (L) Dual Slot |
| 重量 | 308 g (ロープロファイルブラケット時)、320 g (ATXブラケット時) |
| Thermal Solution | アクティブファン |
| 3D Vision/3D Vision Pro | Support (3-pin mini DIN経由) |
| Frame lock | 互換(Quadro Sync II経由で) |
| NVLink | 未対応 |
| NVLink Interconnect | 未対応 |
| NVENC | NVDEC | 2x | 2x (AV1 encode & decodeにも対応) |
表3 NVIDIA RTX 4000 SFF Ada世代のスペック(NVIDIA社の資料より筆者作成)
今回はノートPC向けのNVIDIA RTX Ada世代 Laptop GPUと、NVIDIA RTX 4000 SFF Ada世代が新しく追加製品として発表されている。いずれもRTXの製品群を拡張し、いわゆるメタバース向けのコンテンツを作るクリエイターや3D CAD/CAMなどにより高い性能を提供する製品となる。
生成AIが「学習でもGPU、推論でもGPU」という潮流を加速していくことを示唆していたGTC
 学習でもGPU、推論でもGPUという流れが今後加速していく(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
学習でもGPU、推論でもGPUという流れが今後加速していく(出典:GTC: Spring 2023 Keynote Deck、NVIDIA)
このように、今回のGTC 2023では、昨年のGTC 2022(春)でNVIDIA H100 GPUが発表されたように、学習向けの新しいハードウエアが発表されたという訳でなく、昨年発表されたDGX H100の大量出荷が始まり、まもなく出荷が開始されるというのが最も大きなニュースになる。学習時の性能をさらにあげたいと、DGX H100の導入を検討していたユーザーにとってはもちろんいいニュースで、まもなくGDEP社のようなNVIDIAのリセーラーを通じて入手することが可能になる見通しだ。
その意味では今回のGTC 2023では、生成AIに向けたソリューションが学習も、推論も話題の中心だったと言って良い。NVIDIAは生成AIの領域特化型開発キットとして自然言語処理のための「NeMo」、そして画像生成のための「Picasso」を提供している。それらを組み合わせて利用することで、既に導入されているNVIDIA GPUを活用して生成AIの構築が可能になる。
これまで多くのエンタープライズでは学習はGPUで、推論はCPUでという区分けをしているところが多かったと思う。しかし、生成AIの登場がそれを変えようとしており、推論もGPUでという動きは今後加速していく可能性が高い。GPUを利用して推論を行なうソリューションに関しては「NVIDIA TensorRT」というソフトウエアが提供されており、それとNVIDIA H100 PCIeや今回発表されたNVIDIA H100 NVLを組み合わせて利用することが可能になる。
どこかのオリンピアンではないが、「学習でもGPU、推論でもGPU」、そうした動きが加速していくことを示唆していたのが、今回のNVIDIAのGTC基調講演ということができるのではないだろうか。
笠原一輝


