


search製品名・スペックから検索






NVIDIA RTX PRO 6000 Blackwell シリーズ製品比較ベンチマークレポート
― 大規模AI開発ワークフローへの導入に向けた提言 ―
1. 概要
NVIDIA RTX PRO 6000 Blackwellシリーズは、共通の高性能GPUアーキテクチャ(Blackwell)と大容量96GB GDDR7メモリを基盤としながら、適用されるTDP(最大消費電力)と冷却方式(フォームファクタ)によって3つのエディションに分化されています。これは、AI開発ワークフローにおける異なる設置環境(ハイエンドワークステーション、小型/マルチGPU構成、データセンター)に最適化するためです。
本レポートでは、ベンチマークを通して、各エディションの技術的特徴、導入メリットを整理し、導入検討のための基礎情報を提供します。
2. 各エディションの性能比較
|
製品型番 |
RTX6000 Blackwell Max-Q Workstation Edition |
RTX 6000 Blackwell Workstation Edition |
RTX 6000 Blackwell Server Edition |
|
製品写真 |
|
|
|
|
主な用途 |
省電力・小型WS マルチGPU構成 |
ハイエンド デスクトップWSでの最高性能 |
データセンター ・サーバー向け |
|
最大消費電力 (TDP) |
300 W |
600 W |
400 W ~ 600 W (設定可能) |
|
冷却 |
ブロワー式 (シングルファン) |
ダブルフロースルー (デュアルファン) |
パッシブ冷却 (ファンレス) |
|
フォームファクタ |
小型/短めサイズ (4.4″ H x 10.5″ L) |
標準的な大型サイズ (5.4″ H x 12″ L) |
短めサイズ (サーバーラックに最適化) |
|
単精度性能 (FP32) |
110 TFLOPS |
125 TFLOPS |
117 TFLOPS |
|
RTコア性能 |
333 TFLOPS |
380 TFLOPS |
352 TFLOPS |
|
特徴 |
電力効率が良く、小型筐体や 複数GPU構成に最適。 |
単体で最高のパフォーマンス、 強力な冷却。 |
高密度サーバー環境に特化、 冷却に依存しない。 |
|
注意点 |
最大性能は Workstation Editionに劣る。 |
消費電力と発熱が最大。 |
パッシブ冷却のため、 サーバー筐体の 強力なエアフローが必須。 |
3. ベンチマーク
3.1 旧世代と現行世代各エディションの性能比較ベンチマーク
まずは旧世代のRTX 6000Adaと新世代のRTX 6000Blackwellの各エディションを比較しました。
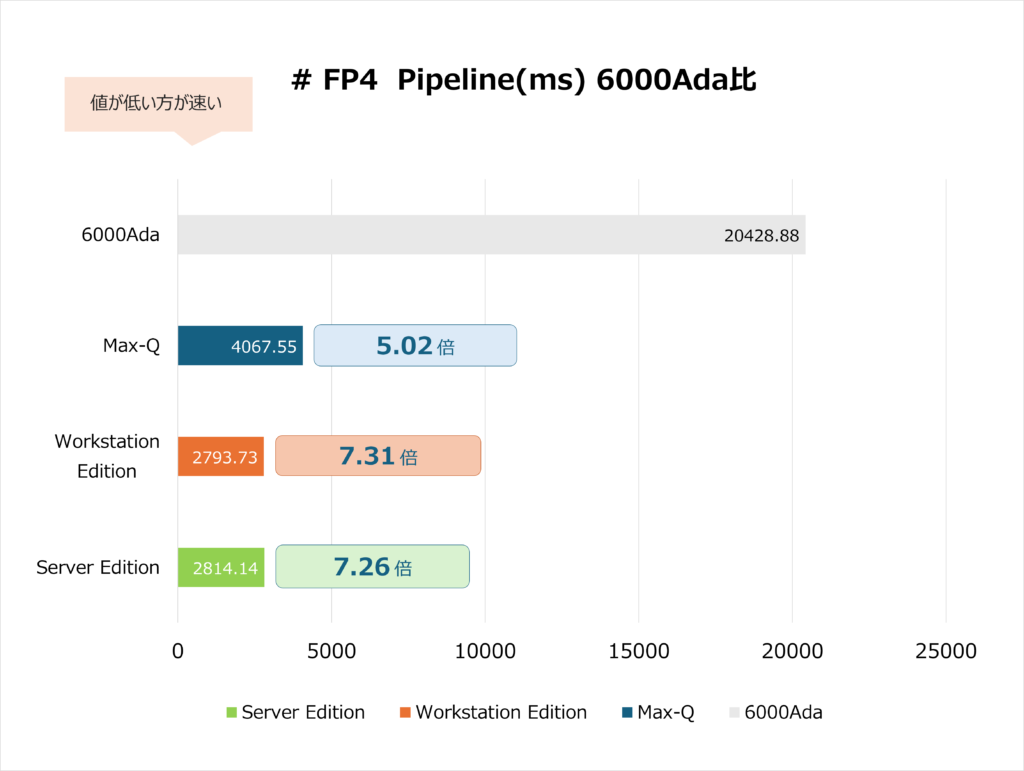
上のグラフはNVIDIAのプロフェッショナル向けGPUラインアップにおける、FP4データ処理パイプラインの実行時間(ミリ秒)を比較したものです。比較対象は、旧世代の「6000Ada」と、新世代Blackwellの「Max-Q」、「Workstation Edition」、「Server Edition」の3つのエディションです。
FP4(4ビット浮動小数点)は、AIの推論や大規模モデルの実行において、高速かつ低メモリ消費で処理するために重要なデータ形式です。
旧世代の「6000Ada」の処理時間が 20,428.88 ms であるのに対し、新世代Blackwelの3エディションは、すべて4,067.55 ms以下という大幅な時間短縮を実現しています。
最も高性能な「Workstation Edition」は、6000Adaの約7.31倍の高速化(処理時間を約1/7.3に短縮)を達成しており、これはGPUのアーキテクチャ、特にTensorコアの進化と、FP4のような低精度演算に特化した最適化が劇的に進んだことが要因です。
3.2 新世代エディション間の性能比較
次にBlackewell世代のエディションでの性能比較を行いました。
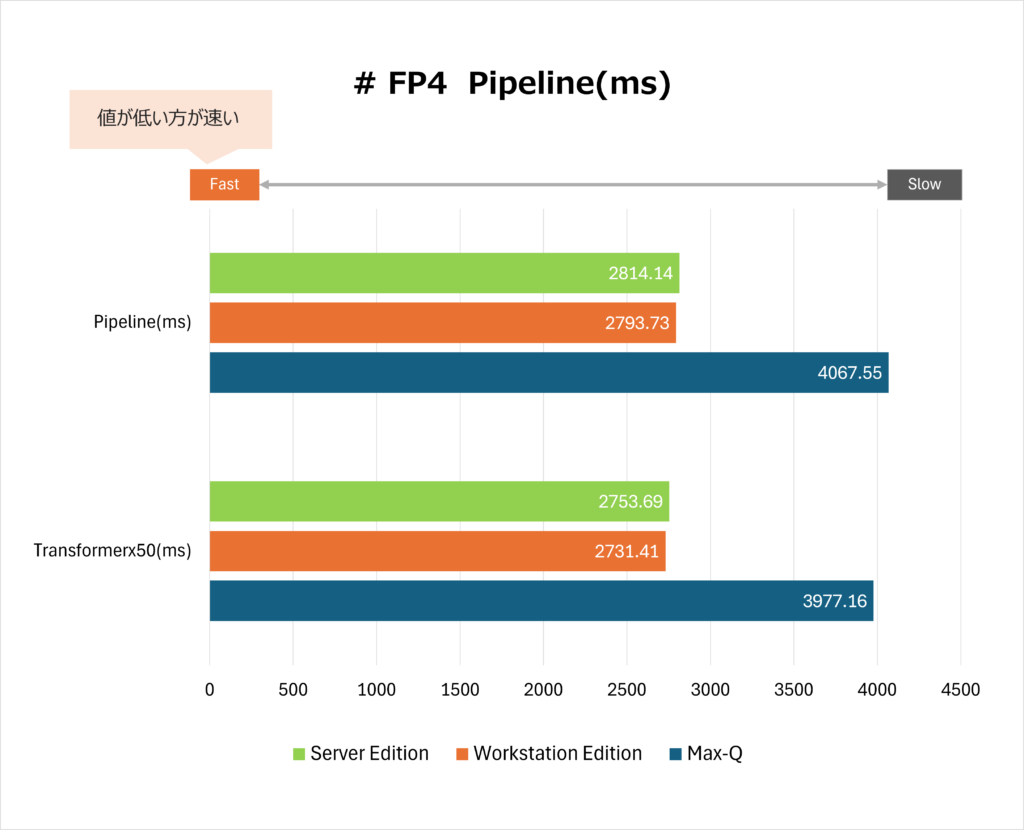
一般的なFP4データ処理パイプラインの実行時間に加えて、大規模言語モデル(LLM)などで用いられるTransformerアーキテクチャの処理(50層)の実行時間も計測してみました。
両方のベンチマークにおいて、エディション間の性能順位は一貫しています。
・Workstation Edition:いずれのテストでも最も優れた処理速度(最短時間)を記録しました。
・Server Edition:Workstation Editionとほぼ同等の性能を示しています。
・Max-Q:他の2エディションと比較して処理時間が長くなっています。
この結果は、Workstation EditionとServer Editionが、それぞれ600Wに近い高TDP(熱設計電力)設定を許容することで、GPUのコア性能を最大限に引き出しているのに対し、Max-Qは厳格なTDP制限(通常300W)によってクロック速度が抑えられているという、設計上の特性を明確に反映しています。
Transformerx50 の処理時間は、Pipeline の処理時間よりも、すべてにおいてわずかに短くなっています。これは、Transformerx50のワークロードが、GPUのアーキテクチャやFP4最適化(特にTensorコアの機能)に対して、より効率的に実行されるようにチューニングされていることを示唆します。
最も高性能なWorkstation Editionで見ると、Transformerx50(2,731.41 ms)はPipeline(2,793.73 ms)より約2.2%速く処理されています。
このベンチマーク性能比較から、次のような導入指針が導かれます。
最高性能と最短時間:
AI推論、LLM実行、複雑なデータパイプライン処理において絶対的な最高速度を求める場合は、Workstation Edition(デスクトップワークステーション向け)が最適な選択肢となります。
高密度と高性能の両立:
データセンターやサーバールーム環境で高密度にGPUを配置しつつ、Workstation Editionに匹敵する高性能を求める場合は、Server Edition(パッシブ冷却/サーバー向け)が適しています。
電力効率と設置柔軟性:
小型筐体や電力・熱の制約が厳しい環境で導入する場合、Max-Qが選択肢となります。FP4関連の処理速度は他の2エディションに比べて低下しますが、その分複数毎のGPUカードを100V環境で利用できるという大きなメリットがあります。デスクサイドでのAI開発を手軽にスピーディーに行いたいが、GPU性能は妥協したくないという要求にマッチするバランスです。
4. 各エディションの特徴と導入検討ポイント
4.1. Max-Q Workstation Edition
● 定義 : 省電力性、電力効率、および小型化を重視したワークステーション向けモデル。
【技術的強み】
電力効率:

TDPを300Wに制限することで、発熱を抑えながら高い性能を維持し、電力コストを抑制します。100V環境下の居室で高性能なマルチGPUのAI開発環境を構
築できる有力な選択肢となります。
柔軟な設置:
コンパクトな設計とブロワー式冷却により、小型ワークステーションや、複数のGPUを搭載するマルチGPU構成の導入が容易になります。特に、複数のセンサーデータ処理を同時に行うような、GPUメモリ総容量を重視するタスクに有効です。
【導入上の検討事項】
ピーク性能の制約:
Workstation Editionと比較し、TDP制限のため単一GPUの最大演算性能は若干低下します。
4.2. Workstation Edition
● 定義 : 最高のパフォーマンスを許容する大型デスクトップワークステーション向けモデル。
【技術的強み】

絶対性能の最大化:
600WのTDP設定により、単一GPUにおけるFP32性能とRTコア性能のピーク値が最も高く、大規模な車両シミュレーションやAIモデルの初期トレーニング時間を短縮します。
強力な冷却:
デュアルファンによるダブルフロースルー設計は、高負荷連続稼働時でも性能低下を最小限に抑えます。
【導入上の検討事項】
消費電力と排熱:
600Wの消費電力と発熱に対応するため、確実な廃熱に対応した筐体と強力な電源ユニット(PSU)が必須となります。
4.3. Server Edition
● 定義 : データセンターやサーバーラック環境への高密度実装に特化したファンレスモデル。
【技術的強み】
高密度実装:

ファンレス(パッシブ冷却)設計により、サーバーラック内で隣接するカードとの間にスペースを取らず、GPU密度を最大化できます。
電力最適化:
サーバー筐体のエアフロー能力に応じて、TDPを400Wから600Wの範囲で柔軟に設定でき、AI推論や仮想化環境での安定稼働に貢献します。
【導入上の検討事項】
専用環境の必要性:
カード単体での冷却能力がないため、必ず強力な冷却システムを備えた専用のサーバー筐体内での運用が必須となります。
5. まとめと推奨される導入シナリオ
| img |
開発ワークフロー |
推奨エディション |
選択理由 |
 |
マルチGPUによる大規模データ処理 |
Max-Q Workstation Edition |
低消費電力で複数枚搭載し、総GPUメモリー容量を稼ぎつつ発熱を抑制。 |
 |
大規模AIモデルの初期トレーニング |
Workstation Edition |
最高のTFLOPS性能がトレーニング時間を最短化する。 |
 |
シミュレーション・リアルタイム視覚化 |
Workstation Edition |
高いRTコア性能とメモリ帯域が、複雑なレイトレーシング処理を加速。 |
 |
データセンターでのAI学習・推論・仮想化 |
Server Edition |
高密度実装によるリソースの集約と、柔軟な電力設定が可能。 |
利用するアプリケーションのピーク性能要求、設置場所の熱/電力制約、データセンターかローカルワークステーションか、などの環境要件に基づいて、最適なエディションを選択が可能です。
詳しくはジーデップ・アドバンス営業までお気軽にご相談ください。


