


search製品名・スペックから検索






エンタープライズストレージシステムの必要性

NVIDIA DGX SuperPODのような世界最高峰のAIスーパーコンピューターにおいて、ストレージは単なる「データの保存場所」ではなく、「計算速度を決定づけるエンジンの一部」として扱われます。
GPUが超高速になりそれらを接続するネットワークが広帯域になればなるほど、ストレージの性能がボトルネックになり、投資対効果(ROI)を劇的に下げてしまいます。これを防ぐために専用ストレージが必要です。
ハイエンドなエンタープライズストレージでは、特に以下の3点が重要なファクターです。
![]()
データ転送速度(スループット)
- GPUを待たせない圧倒的なデータ転送速度 -
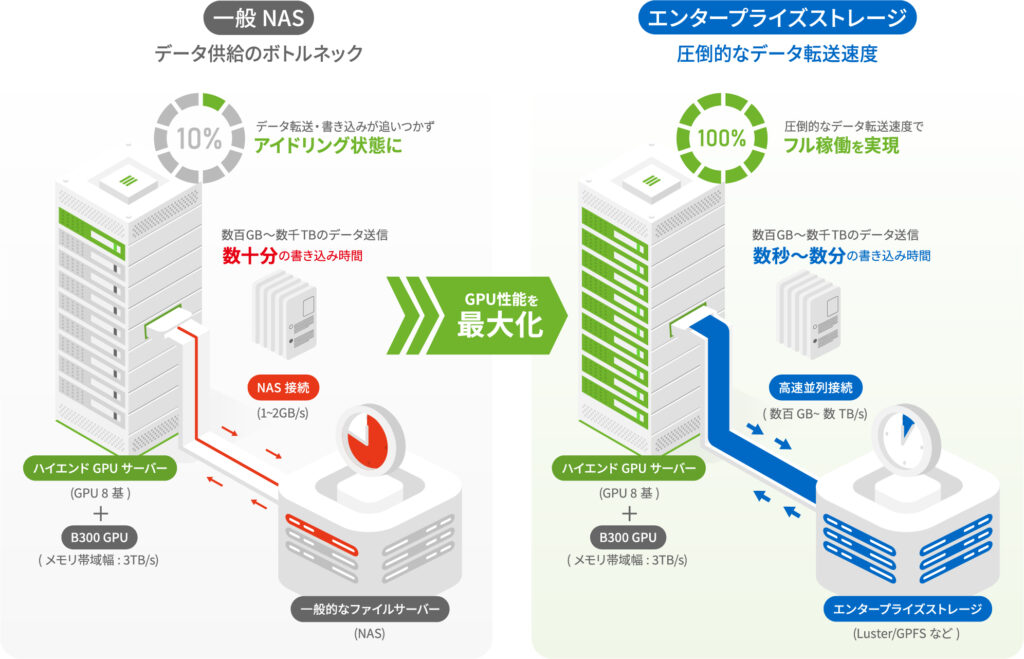
AI学習、特に大規模言語モデル(LLM)や画像認識の学習では、「計算している時間」よりも「データを読み込んでいる時間」の方が長くなるという逆転現象が起きがちです。
例えば最新のNVIDIA GPU「B300」を搭載したDGX B300システムを例にします。
GPUのメモリ帯域幅は 約8TB/秒(B300 SXM 1基あたり)と超高速でデータを飲み込んで処理します。
DGX 1ノード(GPU 8基)が必要とするデータ供給速度は学習モデルによりますが、数十GB/秒 〜 100GB/秒以上 の読み込み速度が要求されることがあります。これに対して一般的なファイルサーバー(NAS)の速度はせいぜい 1GB/秒 〜 2GB/秒 程度です。
| もし一般的なNASをDGXに接続すると、GPUは処理能力の90%以上の時間を「データが来るのを待つ(アイドリング)」ために費やすことになります。 |
1台数千万円するDGXを、ただの待機状態にしておくのは莫大な損失です。
エンタープライズストレージは並列ファイルシステム(LustreやGPFS/Spectrum Scaleなど)を採用しており、数百GB/秒〜数TB/秒という、桁違いのデータアクセススピードを実現できます。これによりGPUの待機時間を最小限に抑えることが可能です。
中でも特に重要なのがチェックポイントの書き込みです。AI学習中は、数時間に一度、AIモデルのバックアップ(チェックポイント)を保存します。
大規模モデルの場合、そのサイズは 数百GB 〜 数TB になり、DGX SuperPod(例えば32ノード)全体で一斉に保存をかけると、数十TBのデータが一瞬で発生します。
| 一般的なストレージであれば書き込みに数十分かかり、その間すべての学習がストップします。エンタープライズ高速ストレージなら、これを数秒〜数分で終わらせ、すぐに学習を再開できます。 |
![]()
外部データ連携(ワークフロー)
― 開発にコミット出来るデータの「移動と鮮度」-
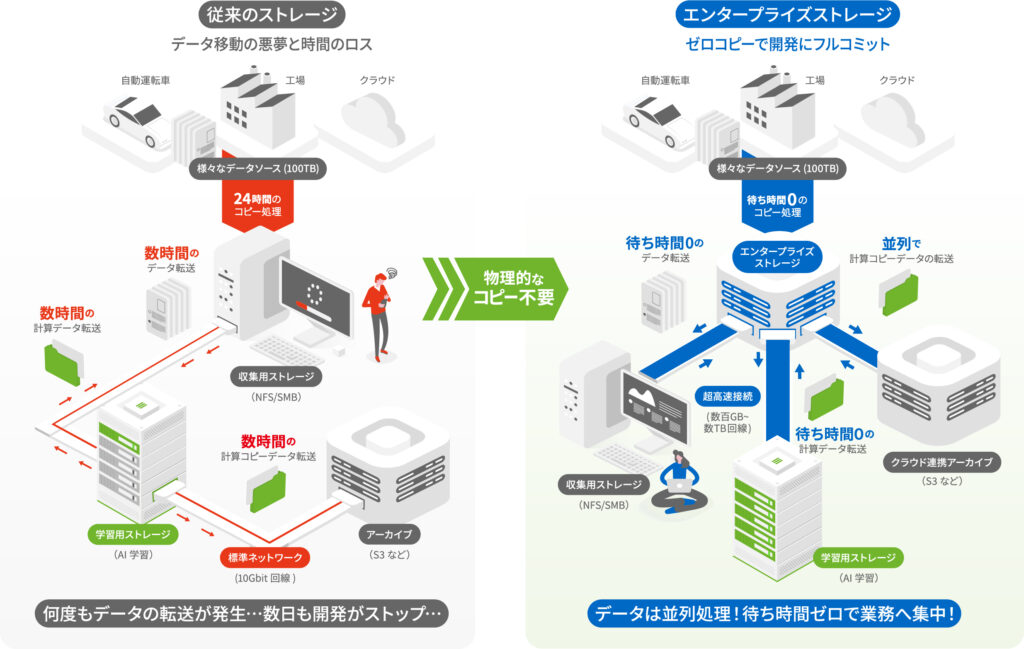
ご存じの通りAIシステムは孤立して存在しているわけではありません。工場、研究所、クラウドなど、外部からデータを持ってくる必要があります。
例えば自動運転車のデータ処理で言えば、開発車両が1日走行して集めたセンシングデータ田や画像データが 100TB あるとします。これを普通のストレージを使って、AI学習用のストレージへ送り込むとすると、10Gbit回線で約24時間かかり、学習完了後、結果をアーカイブへコピーするところで、また膨大な時間を要します。データの「移動」だけで数日ロスする計算です。
対して、エンタープライズストレージは、異なるプロトコル(データの疎通言葉)を同時に話せます。
|
・ NFS/SMB: データの収集・整理をするPCからは、普通のフォルダとして見える。 ・ GPFS/Lustre/NFS over RDMA: DGXからは、超高速な並列ストレージとして見える。 ・ S3: クラウド(AWSなど)との連携が可能。 |
というように
| ローデータの保存 ▶ 計算時のアクセス ▶ アーカイブ |
という流れでフェーズごとにその都度データをたらい回しにする必要がありません。
「データを物理的にコピー・移動せず」に、収集したデータをそのままGPUで超高速に読み込むといった構成(あるいはバックグラウンドで自動的に階層化移動)が可能になります。 100TBのコピー時間をゼロにできる、ということは本来の「分析・開発」にフルコミットできるようになるということであり、ビジネススピードにおいて決定的な差になります。
![]()
「同時アクセス」への耐性(メタデータ性能)
― GPUやネットワークを遊ばせない一番大事な性能 ―
最後に、数字には表れにくいですが極めて重要な点「メタデータ性能」です。
一言で言うと、メタデータ性能とは「ファイルの中身を読む速さ(スループット)」ではなく、「ファイルを見つけ出し、開き、閉じる速さ(IOPS/レイテンシ)」のことです。
AI/HPC環境において、ここがボトルネックになると、いくら帯域幅(Bandwidth)が太くてもシステム全体のパフォーマンスは劇的に低下します。
そもそもデータとは、
|
①実データ(ファイルの中身そのもの。画像ピクセル情報やテキスト本文など) ②メタデータ(ファイルを管理するための情報:ファイル名、パス、作成日時、アクセス権限、地番) |
に分けられます。
通常のファイルアクセスは、まず②のメタデータを参照して、①の実データを読み込みます。
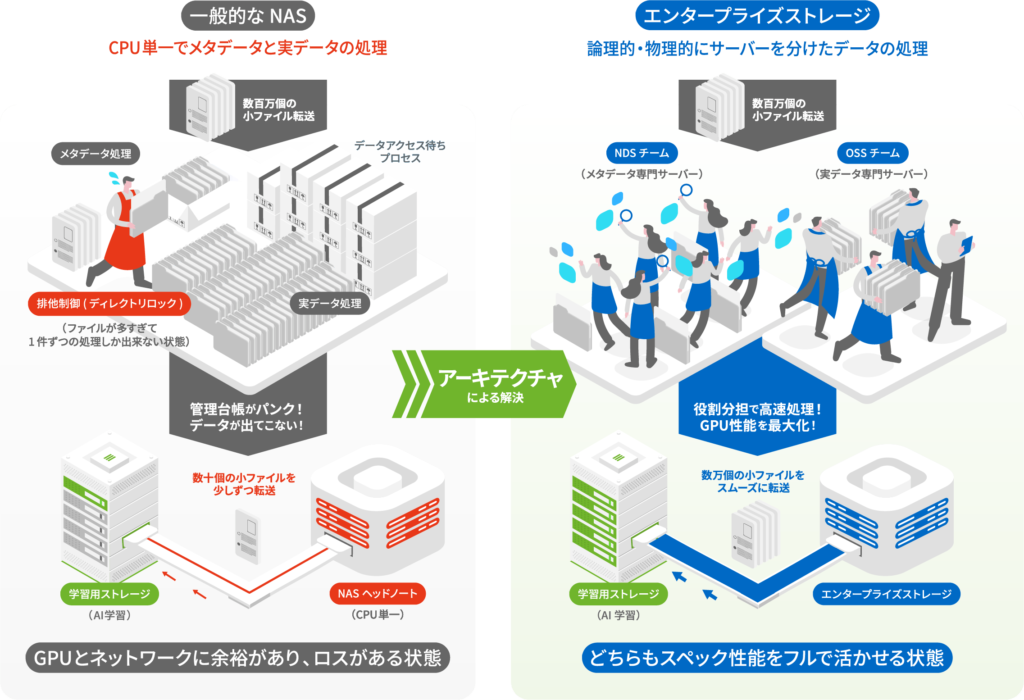
ここにAI学習特有の課題が出てきます。AI学習(特にコンピュータビジョンや自然言語処理)では、「Small File」と呼ばれる数KB〜数MBの小さなファイルが数百万〜数億個存在します。
一般的なNASではメタデータ処理を単一のCPU(ヘッドノード)で処理することが多く、GPUクラスターが膨大なデータ、例えば1万枚の画像を一斉に共有した際にCPUの処理待ちが発生します。加えて「ディレクトリロック」と言われる排他制御があり、特定のファイルを検索、作成する際に、そのディレクトレリ全体にロックが掛かり、他のプロセスが止まります。
| 結果として「GPUは空いている、ネットワークも空いている、でもストレージの管理台帳(メタデータサーバー)がパンクしていてデータが出てこない」という現象が起きます。 エンタープライズストレージはこの問題をアーキテクチャレベルで解決しています。 メタデータを処理するサーバー(MDS:Metadata Server)と、実データを送るサーバー(OSS:Object Storage Server)を物理的・論理的に分けています。 |
例えるなら、一般的なNASが、品出しもレジ打ちも店長一人で行っているワンオペのコンビニエンスストアだとすると、エンタープライズストレージは、品出し専門職人(OSS)、レジ打ち専門職人(MDS)が何十人もいる大規模スーパーマーケットのようなものです。1万人がレジに殺到しても秒で捌けます。
大規模AI基盤において、エンタープライズストレージが必要な最大の理由は、単に「太い土管(スループット)」を持っているからだけでなく、この「超高速なメタデータ処理能力」を持っているためです。


