


search製品名・スペックから検索






GTC 2026春 基調講演レポート 特別寄稿 笠原一輝
NVIDIA、「Vera Rubin」「Groq 3 LPU」投入でAI推論市場でも覇権確立へ
 GTCで講演するNVIDIA CEO ジェンスン・フアン氏
GTCで講演するNVIDIA CEO ジェンスン・フアン氏
NVIDIAが開催しているGTCは、春に米国カリフォルニア州サンノゼで開催される「GTC」と、秋に米国首都ワシントンD.C.で開催される「GTC D.C.」の年2回開催される同社の年次イベントだ。春のGTCは、主に新しいハードウェア製品に特化した内容になっており、例年同社の新GPUや新GPUを搭載したラックデザインが発表される場となっている。
3月16日~3月19日(現地時間)にサンノゼ市の各会場で開催されたGTC 2026では、NVIDIA CEO ジェンスン・フアン氏の基調講演などで1月のCESで発表された新CPUの「Vera」、GPUの「Rubin」、そしてそれらを1ラックに収めた「Vera Rubin NVL72」などが改めて説明されたほか、昨年NVIDIAが非独占ライセンス契約を明らかにしたGroq社が開発したLPUを、NVIDIAのAIソリューションの一部として活用することや、Vera CPU 256基から構成される「Vera CPU Rack」が発表され、2027年~2028年に向けたロードマップなどが明らかにされた。
NVIDIAが今回、そして1月のCESで発表したハードウェアは、いずれも推論市場に最適化された製品になっており、2027年に1兆ドルを超える市場規模があると予測されるVera Rubinで、従来の学習に加えて、推論市場でも覇権確立を目指す。
2年に一度新アーキテクチャのGPU、中間年にメモリ増加の新製品~1年に一度新しい製品が出てくるNVIDIA GPU
 NVIDIAがCESで発表したRubin
NVIDIAがCESで発表したRubin
春のGTCでは、NVIDIAのAIインフラ向けのハードウェア製品が発表されるのが通例だ。このGTCで新製品を発表し、その年のうちに実際に製品として投入されるというのがここ数年のパターンだ(いくつかは発売が翌年にずれ込むこともあるが……)。
NVIDIA ハイパースケーラー・HPC担当 副社長 イアン・バック氏は、今回のGTCにおいて「1年に一度新製品を投入するというのが同社のAI向け半導体戦略だと説明する。
たしかに2022年のH100、2023年のH200、2024年のBlackwell(B200/B100)、2025年のBlackwell Ultra(B300)と1年に一度新製品が発表され、その年のうち、あるいは翌年に投入されてきたのがここ5年のNVIDIA AI向け半導体の歴史だ。
|
発表年 |
2022年 |
2023年 |
2024年 |
2025年 |
2026年 |
|
GPU単体名 |
H100 |
H200 (SXM) |
B200 (Blackwell) |
B300 (Blackwell Ultra) |
Rubin |
|
GPUアーキテクチャ |
Hopper |
Hopper |
Blackwell |
Blackwell |
Rubin |
|
GPUメモリ/チップ |
80GB HBM3e |
141GB HBM3e |
186GB HBM3e |
288GB HBM3e |
288GB HBM4 |
|
メモリ帯域幅 |
3.35TB/秒 |
4.8TB/秒 |
8TB/秒 |
8TB/秒 |
22TB/秒 |
|
NVLink |
NVLink 4 (900GB/秒) |
NVLink 4 (900GB/秒) |
NVLink 5 (1.8TB/秒) |
NVLink 5 (1.8TB/秒) |
NVLink 6 (3.6TB/秒) |
|
NVFP4 (Tensor) |
未対応 |
未対応 |
20PFLOPS |
20PFLOPS*2 推定 |
50(推論)/35(学習)PFLOPS |
|
FP8 (Tensor) |
3958TFLOPS |
3958TFLOPS |
10PFLOPS |
10PFLOPS*2 推定 |
17.5PFLOPS |
|
INT8 (Tensor) |
3958TFLOPS |
3958TFLOPS |
?*1 |
?*1 |
0.25POPS |
|
FP16/BF16(Tensor) |
1979TFLOPS |
1979TFLOPS |
5PFLOPS |
5PFLOPS*2 推定 |
2PFLOPS |
|
TF32 (Tensor) |
989TFLOPS |
989TFLOPS |
2.5 PFLOPS |
2.5 PFLOPS*2 推定 |
2PFLOPS |
|
FP64 (Tensor) |
67TFLOPS |
67TFLOPS |
40TFLOPS |
40TFLOPS*2 推定 |
33TFLOPS |
NVIDIAのAI向け半導体(NVIDIA社の資料などより筆者作成)
*1 NVIDIAの公式スペックではB200のINT8は10 POPSとなっているが、Rubinの40倍の性能を持つことになりVera Rubin NVL72よりも高性能となるためなんらかの間違いだと考えられる。そのため?としている
*2 NVIDIAはGB300単体のスペックを発表していないが、GB300 NVL72とGB200 NVL72のスループットなどが同じであることから、GB300もGB200と同じスペックだと考えられるため
ただし、よく見ればわかるように、毎年完全に新しいアーキテクチャが投入されているかというとそうでもなく、2022年にはHopperアーキテクチャの最初の製品になるH100が発表され、翌年にはそのメモリ増加版となるH200が発表されている。2024年に発表されたBlackwellも同様でB200/B100が発表され、翌年にそのメモリ増加版となるB300(Blackwell Ultra)が投入されている。このように、まずは新しいアーキテクチャのGPUが投入され、翌年にメモリ増加版が投入されるという形で新製品が毎年投入されるというのがNVIDIAの基本戦略となる。
それでは、本年はどうかと言うと、1月に開催された、CESでの記者会見の中で「Rubin」が発表されている(このため、今回のGTCでは新製品の発表は、後述するLPUだけになっている)。なお、Rubin以前はBlackwellならB300、B200、B100と開発コードネームとは別に製品名が用意されていたが、Rubinからは開発コードネームがそのまま製品名になっている。そのため、今回はR100やR200という製品名は用意されず、ただ「Rubin」と呼ばれている。つまりRubin世代ではB100やB200のように、スペック違いのSKUは用意されないということだ。
Rubinの特徴はハイレベルで見ると3つある。それが内部エンジンの進化、メモリ周りの強化、そしてNVLinkの強化だ。
内部エンジンは、同社が第3世代Transformerと呼んでいるエンジンに強化されている。NVIDIAはRubinの内部アーキテクチャなどに関して詳しい説明はしていないが、公表されたスペックを見ると、NVFP4利用時の性能が50PFLOPSと、Blackwell世代の2.5倍になっている。同様にFP8もBlackwell世代の10PFLOPSから17.5PFLOPSと75%向上していることがわかる。
その逆にFP16/BF16(Tensor)、TF32(Tensor)やFP64(Tensor)はむしろ前の世代よりも下がっている。例えば、FP16/BF16(Tensor)などは、Hopper世代とほぼ同じ性能になっており、第3世代Transformerエンジンが、NVFP4を利用した推論のピーク性能に特化した設計になっていることがうかがえる。
Hopper世代からBlackwell世代まで、メモリはHBM3eが利用されてきたが、今回のRubinではHBM4に強化されている。HBM4はピンあたりの帯域幅が11Gbpsに強化されており、GPUレベルの帯域幅は8TB/秒から22TB/秒へと大幅に引き上げられている。さらにチップの積層数も12層と16層を実現可能になっており、将来のアップグレードに備えられる。
Rubin出荷時のHBM4の積層数は12層とHBM3eと同じであるため、Rubinのメモリ容量は288GBとB300と同じ。しかし、16層に対応しているため(メモリベンダーは既に16層に対応したHBM4の試作を完了している)、将来製品では384GBへとアップグレードすることが可能になる。NVIDIAはRubin Ultraを2027年に計画しており、そうした製品ではメモリが384GBに強化される可能性が高い。
 NVLink 6 Switch
NVLink 6 Switch
また、GPUのスケールアップ(ラック内部でのGPUのクラスター化)に利用するNVLinkも第6世代に強化されており、チップ間の帯域幅が3.6TB/秒とBlackwell世代の第5世代NVLink(1.8TB/秒)と比較して2倍の帯域幅を実現している。
GTCではVeraの詳細を公開。SMTに対応し、最大1.5TBのLPDDR5をSOCAMM2で実装できる仕様
 GTCに展示されていたVera Rubin NVL72
GTCに展示されていたVera Rubin NVL72
NVIDIAは2024年にBlackwellを発表した時に、ラックレベルの標準デザイン(NVL72)を、GB200 NVL72として投入した。GB200 NVL72は、CPUのGraceを1基、GPUのBlackwellを2基搭載した基板(Grace Blackwell Superchip)を36枚格納し、NVLink Switchの基板、電源ユニットなどを48Uのラックに収め、NVIDIA自身やOEMメーカーなどが顧客に販売する形で提供している。顧客はそのGB200 NVL72に、InfiniBand/EthernetコントローラとしてConnextX-8などのネットワークを利用してスケールアウトすることで、より大規模なGPUクラスターを構築して、AIデータセンターを構築することを可能にしている。昨年にはそのB300版となるGB300 NVL72が発表されている。
|
発表年 |
2024年 |
2025年 |
2026年 |
|
ラックデザイン名 |
GB200 NVL72 |
GB300 NVL72 |
Vera Rubin NVL72 |
|
GPU |
B200/B100(Blackwell)(72基) |
B300(Blackwell Ultra)(72基) |
Rubin(72基) |
|
CPU |
Grace(36基) |
Grace(36基) |
Vera(36基) |
|
LPU |
ー |
ー |
Groq 3 LPU(LP30) |
|
NVLink Switch |
NVLink 5 Switch (1.8TB/秒) |
NVLink 5 Switch (1.8TB/秒) |
NVLink 6 Switch (3.6TB/秒) |
|
イーサネット/InfiniBand |
ConnextX-8 |
ConnextX-8 |
ConnectX-9 |
|
DPU |
BlueField-3 |
BlueField-3 |
BlueField-4 |
|
CPO |
ー |
ー |
Spectrum-X 1024T |
|
CPUメモリ/チップ |
480GB/LPDDR5 |
564GB/LPDDR5 |
1.5TB LPDDR5 |
|
CPUメモリ容量/ラック |
17TB |
20TB |
54TB |
|
GPUメモリ/チップ |
186GB HBM3e |
288GB HBM3e |
288GB HBM4 |
|
GPUメモリ容量(帯域幅) /ラック |
13.4TB (576TB/秒) |
20TB (575TB/秒) |
20.7TB (1,580TB/秒) |
|
NVFP4(Tensor)/ラック |
1440PFLOPS |
1440PFLOPS |
3600(推論)/2520(学習)PFLOPS |
|
FP8(Tensor)/ラック |
720PFLOPS |
720PFLOPS |
1260PFLOPS |
|
INT8(Tensor)/ラック |
24 POPS(*筆者推定*1) |
24 POPS |
18 POPS |
|
FP16/BF16(Tensor)/ラック |
360 PLOPS |
360 PFLOPS |
288PFLOPS |
|
TF32(Tensor)/ラック |
180PFLOPS |
180PFLOPS |
144PFLOPS |
|
FP64(Tensor)/ラック |
2,880 TFLOPS |
2,880 TFLOPS (*2筆者推定) |
2,400 TFLOPS |
Vera Rubin NVL72などのNVL72のスペック(NVIDIA社の資料などより筆者作成)
*1 NVIDIAの公式スペックではGB200 NVL72のINT8は720 POPSとなっているが、GB300NVL72が24 POPSであることと整合性なく、何らかの誤りだと考えられるため、GB300 NVL72と同じ24 POPSとしている
*2 NVIDIAのGB300 NVL72のFP64は公式スペックでは100TFLOPSと書かれているが、GPU1つの性能並みになってしまっているため、何か間違いだと考えられる。そこでGB200 NVL72と同じ性能だと仮定している
本年のCESでは、その最新版としてVera Rubin NVL72が発表されている。Vera Rubinは、従来のGB200、GB300で採用されていたGB200 Superchip、GB300 Superchipにかえて、Vera Rubin Superchip(CPUのVeraが1つ、GPUのRubinが2つ)が1つのラックに36枚格納されており、Veraが36基、Rubinが72基、それぞれラック内に格納されている。
|
|
Grace |
Blackwell |
|
デザイン |
Arm Neoverse V2 |
NVIDIA Olympus |
|
アーキテクチャ |
Armv9-A |
Armv9.2-A |
|
コア数 |
72コア |
88コア/176スレッド |
|
L1 |
64KB(命令)+64KB(データ) |
未公表 |
|
L2 |
1MB(コア1つあたり) |
未公表 |
|
L3 |
114MB(ダイ全体) |
162MB |
|
メモリ |
LPDDR5X(基板実装) |
LPDDR5X(SOCAMM2) |
|
容量(帯域幅) |
120~480GB(384~512GB/秒) |
最大1.5TB(1.2TB/秒) |
GraceとVeraのスペック(NVIDIA社の資料などより筆者作成)
CPUのVeraは、GB200/GB300(GBはGrace Blackwell)で採用されていたGraceの後継となる。GraceではArm Neoverse V2のIPデザインが採用されており、1つのダイに72コアが搭載される形になっていた。それに対してVeraでは、NVIDIA自身がデザインした「NVIDIA Olympus」がCPUコアデザインとして採用されており、1つのダイに88コアが搭載されている。しかも、いわゆるSMT(Simultaneous Multi-Threading、仮想マルチスレッディング、1つの物理コアに対して2つのスレッド数を用意すること)に対応しており、ソフトウエアからは176コアのスレッド数があるように見える。
 Vera
Vera
 Veraに採用されているSOCAMM2のLPDDR5メモリ
Veraに採用されているSOCAMM2のLPDDR5メモリ
また、メモリも大きく強化されている。LPDDR5Xが採用されており、メモリの消費電力を下げるようにする取り組みはGraceと同じだが、Graceでは英語で言うところの「Down」と呼ばれるメインボード(マザーボード)上にDRAMを搭載するだけだったのに対して、VeraではSOCAMM2というLPDDR5もメモリモジュール上に実装できる、新しい規格のメモリモジュールに対応。メインボード上に用意されているSOCAMM2のソケットにモジュールを搭載することで、メモリを実装することを可能にする。これにより、メモリ容量は最大1.5TBまで増設可能になっており、より多くのメモリを利用して推論したいというニーズに応えられる。
 BlueField-4とConnectX-9 SuperNIC
BlueField-4とConnectX-9 SuperNIC
 Spectrum-X 1024T CPO
Spectrum-X 1024T CPO
このほかにも、Vera Rubin NVL72世代では、新しいInfiniBand/EthernetコントローラとしてConnectX-9、そのConnectX-9とVera CPUから構成されている、新しいDPUのBlueField-4、さらには光電融合のソリューションとして、シリコンフォトニクスによる光通信を実現するSpectrum-X 1024T CPOなどが発表され、NVLink 6によるスケールアップだけでなく、InfiniBand/Ethernetによるスケールアウトも実現される。
GPUの弱点だったAI推論時の消費電力とメモリ遅延をカバーするためのGroq 3 LPUが登場
 Groq 3 LPU
Groq 3 LPU
今回のGTCでは、そうした1月のCESで発表済みだったVera Rubin NVL72の各コンポーネントに加えて、「Groq 3 LPU」と呼ばれる、いわゆるAI推論アクセラレーターが発表された。
Groqは元々米国で立ち上げられたスタートアップ企業で、LPU(Language Processing Unit)と同社が呼んでいる、新しいAI推論向けのプロセッサーを提供してきた。LPUの特徴は、いわゆるデータフロー・アーキテクチャなどと呼ばれる仕組みを採用していること。
LPUの内部はベルトコンベヤーのように、順次データを処理するパイプラインが用意されており、そこにデータを次々と詰め込んでいくことで、大量のデータを並列に処理して行ける。LPUではローカルメモリとしてSRAMが内蔵されており、基本的なデータはそのローカルメモリにおかれて処理されるため、CPUやGPUのような頻繁なメモリアクセスが必要なく、CPUやGPUの消費電力が高くなる原因の一つとなっているDRAMへのアクセスを抑制できることが特徴。これにより、高い電力効率でデータを処理できる。
 Groq 3 LPUのスペック(基調講演のプレゼンテーションより)
Groq 3 LPUのスペック(基調講演のプレゼンテーションより)
 Groq 3 LPXのブレード
Groq 3 LPXのブレード
NVIDIAは昨年の12月にGroqと非独占ライセンス契約を締結したことを明らかにしており、Groqのアーキテクチャと開発者を活用できるようになっていた。今回発表された開発コードネーム「LP30」ことGroq 3 LPUはその第1弾製品ということになる。
Groq 3 LPUは、Samsungのファウンダリーで製造され、980億のトランジスタから構成されている。NVIDIAがTensor最優先エンジン(Tensor First Compute)と呼んでいるMXM(DensMathMuls)、VXM(Vector Math)、SXM(Switch)の3つのブロックをチップ内に2つ備えており、FP8演算時に1.2PFLOPSという性能を実現している。150TB/秒の帯域幅を実現するSRAMを500MBオンチップ搭載している。NVIDIAはこうしたGroq 3 LPUを256基搭載したラック「Groq 3 LPX」という形で顧客に提供する。
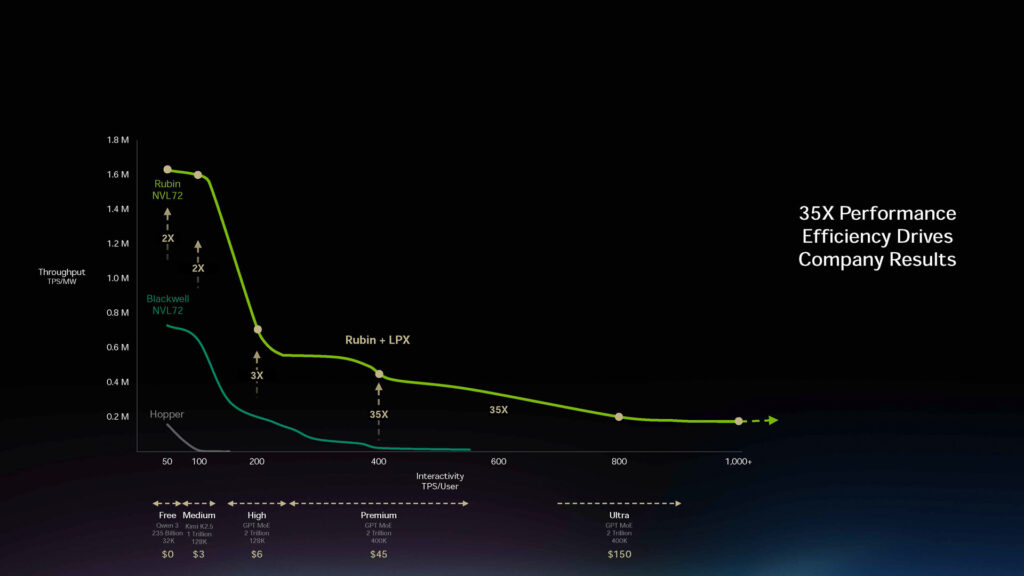
スループット重視にVera Rubin NVL72を、低遅延重視や省電力重視のエリアではVera Rubin NVL72とGroq 3 LPXを組み合わせて利用することを想定している(基調講演のプレゼンテーションより)
こうしたLPUはローカルメモリとしてSRAMを利用することにより低遅延を実現し、DRAMへのアクセスを減らすことでメモリアクセスに起因する電力消費を削減できる。その反面、大容量のデータを素早く処理するという意味でのスループットではGPUにはかなわない。そこで、NVIDIAではVera Rubin NVL72とGroq 3 LPXをセットにして提供することで、スループットの方はGPU、低遅延の方はLPUでと組み合わせカバーしていく戦略だ。
なお、現時点では、CUDAはGroqには対応しておらず、Groqが提供する開発ツールを利用して、Groqで処理を行なう際のスケジューラーの最適化などを行なう必要がある。将来的にはNVIDIAの分散型AI推論フレームワーク「Dynamo」でサポートされ最適化が行えるようになるとNVIDIAは説明している。
 Vera CPU Rack(右のラック)
Vera CPU Rack(右のラック)
 Veraが2チップ搭載されているCPUボード
Veraが2チップ搭載されているCPUボード
このほか、今回のGTCではVera CPUのラックソリューションとなる「NVIDIA Vera CPU Rack」も発表されている。Vera CPU Rackは256基のVeraを1つのラックに格納したもので、2つのVeraが搭載されたCPUボードが128基1ラックに格納されている。ラックあたりの物理CPUコア数は22,518基、論理CPUコアは45,056基となる、モンスターCPUマシンだ。
NVIDIAでは、このVera CPU RackをAIエージェント/エージェント型AIの実行環境と位置づけている。今やAIの注目点は、LLMからAIエージェント/エージェント型AIへと移行しつつあることに異論を持つ人は少ないだろう。今回のGTCでNVIDIAは「OpenClaw」のような、オープンソースで提供されるエージェント型AIのソリューションを何度も取り上げていた。NVIDIA自身も「NemoClaw for OpenClaw」という、OpenClawのセキュリティーを強化するソリューションを発表したほか、フアンCEOの講演でもそのデモを行なうなど、GTCの隠れた主役の1つになっていた。
そうしたAIエージェントやエージェント型AIは、従来型のCPU(具体的にはx86 CPU)上で動かされているのが定番だが、そのオルタナティブとしてNVIDIAが提供するのがNVIDIA Vera CPU Rackとなる。
2027年~2028年のロードマップも公開。Groqは2027年にLP35でNVFP4に対応し、2028年のLP40でNVLinkに対応
 フアンCEOが公開したNVIDIAのロードマップ(基調講演のプレゼンテーションより)
フアンCEOが公開したNVIDIAのロードマップ(基調講演のプレゼンテーションより)
フアンCEOの基調講演では、NVIDIAのAI向け半導体のロードマップも示された。具体的には上のスライドの通りだが、1年に一度更新されるというルールに従って再構築したのが以下の表4となる。
|
|
2026年 |
2027年 |
2028年 |
|
GPU |
Rubin (HBM4) |
Rubin Ultra (HBM4e) |
Feynman (ダイスタッキング,カスタムHBM) |
|
CPU |
Vera |
Vera |
Rosa |
|
LPU |
Groq 3 LPU(LP30) |
LP35(NVFP4対応) |
LP40(NVLink対応) |
|
NVLink |
NVLink 6 Switch (3.8TB秒) |
NVLink 7 Switch (3.8TB秒) |
NVLink 8 Switch(CPO) |
|
イーサネット/InfiniBand |
CX9 |
CX9 |
CX10 |
|
DPU |
BlueField-4 |
BlueField-4 |
BlueField-5 |
|
CPO |
Spectrum 6 102T CPO |
Spectrum 6 102T CPO |
Spectrum 7 204T CPO |
NVIDIAのロードマップ(筆者作成)
既に述べたとおり、NVIDIAのAI半導体は、2年に一度新アーキテクチャGPU、間の年はメモリ増量によるアップグレード版GPUの投入というサイクルで新製品が投入される。本年はRubinという新アーキテクチャの製品が発表されたため、2027年はRubin Ultraというメモリ増量版が投入される。HBM4でも既に可能だが、HBM4eではメモリの積層数が12層から16層へと増やされ、288GBから384GBへとメモリが増量されることになる可能性がある。また、HBM4eというHBM4の改良版になるため、メモリ帯域も引き上げられる可能性が高い。
LPUも強化される。2027年に投入されるLP35では、新しくNVFP4に対応する。これにより、AI推論時の性能がさらに高まることになる。さらにこの世代では中間世代ながら、NVLink Switchの新しいチップが投入される。「NVLink 7 Switch」がそれで、帯域幅は3.8TB秒と同じだが、スイッチできるポート数などが増え、スケールアップできるCPU、GPUの数を増やせる。NVIDIAはGPU144基までスケールアップする「Kyber」というコードネームのラックデザインを計画しており、フアン氏の基調講演ではRubin Ultra、NVLink 7 Switchのモックアップが公開された。
 Kyber向けのNVLink 7 Switch。NVL144を実現することが可能になる。現時点ではチップはモックアップ
Kyber向けのNVLink 7 Switch。NVL144を実現することが可能になる。現時点ではチップはモックアップ
 Kyber向けのRubin Ultraボード、現時点ではチップはモックアップ
Kyber向けのRubin Ultraボード、現時点ではチップはモックアップ
2028年に計画されている「Feynman」(ファインマン)世代では、Feynman自体がダイスタッキングに対応するほか、NVIDIA独自デザインと考えられるカスタムHBMに対応する。また、CPUはLPDDR6に対応するRosaに強化されるほか、LPUはLP40と呼ばれるNVLinkに対応したバージョンが登場する。これにより、ラックの内部でCPU、GPU、LPUを混載することができるようになり、さらにラックの密度を高めることが可能になる。
ネットワーク周りも強化され、SuperNICはConnectX-9からConnectX-10に、DPUはBlueField-4からBlueField-5に、シリコンフォトニクスはSpectrum 6 102T CPOからSpectrum 7 204T CPOへと強化される。それらの強化によりネットワーク周りの性能も強化され、スケールアウト時の効率が高まり、AIデータセンター全体での性能が向上することになる。
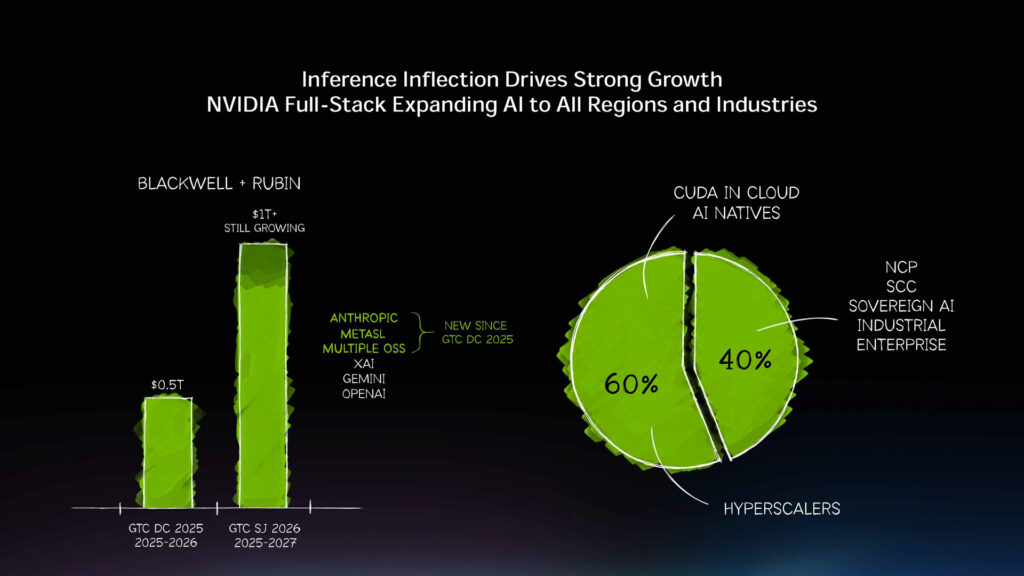 AI推論は転換点を迎えている(基調講演のプレゼンテーションより)
AI推論は転換点を迎えている(基調講演のプレゼンテーションより)
今回の基調講演の中でフアン氏は「AI推論は転換点を迎えている」と何度も繰り返し、昨年のGTCでフアンCEO自身が語ったとおり、今後NVIDIAはAI推論を重視した戦略にシフトしていくことを示した。Grace BlackwellとVera Rubinの潜在市場規模は、2025年~2027年に1兆ドルを超える見通しだとフアン氏は述べ、強い需要が引き続き想定されていることを強調した。それを支えるのがCESで発表されたVera Rubinであり、今回発表されたGroq 3 LPUとなる。そして、さらにその先にも強力なロードマップを用意している。そうしたフアン氏のメッセージが聞こえてきそうなGTCの基調講演だった。


