


search製品名・スペックから検索






RTX 6000Adaと6000 Blackwell Workstation Edition・画像生成の推論速度比較ベンチマーク
2025.08.25
ベンチマーク
RTX 6000Ada・RTX PRO 6000 Blackwell Workstation Edition
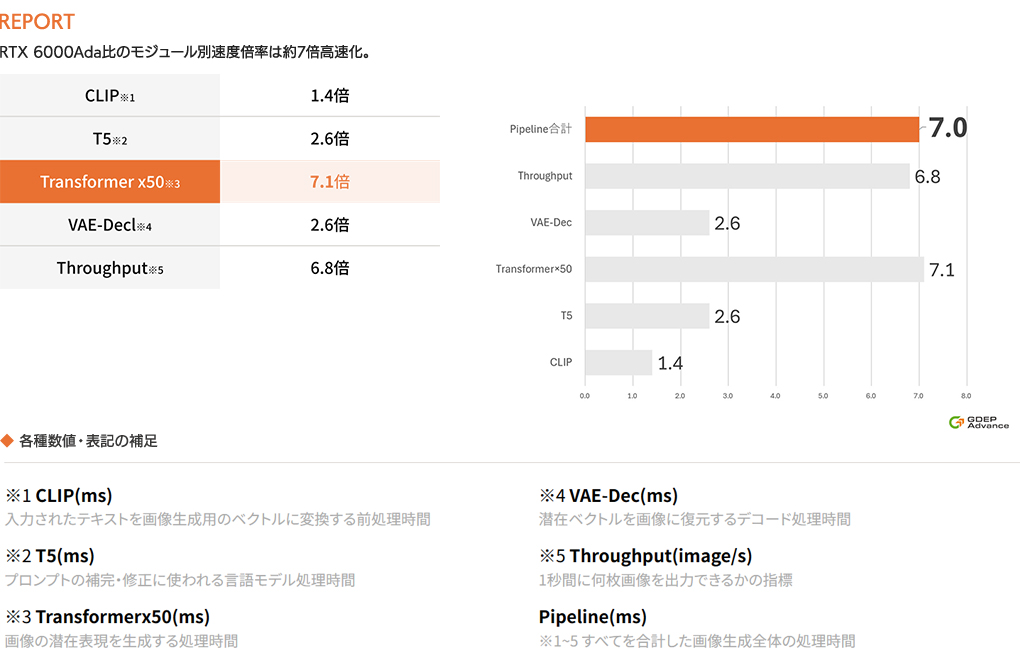
モジュール別およびパイプライン全体における
推論速度の比較結果
GitHub 上で公開されているTensorRT 10.11 デモ環境(Diffusion Pipeline)をベースに、
NVIDIA RTX™ 6000AdaとNVIDIA RTX PRO™ 6000 Blackwell Workstation Editionを用いて画像生成における推論速度を当社の環境で比較ベンチマークを取得しました。
その結果、画像1枚あたりの生成時間(Pipeline全体)がNVIDIA RTX™ 6000Adaと比較して、約7倍高速化されました。
※同シリーズの別型番のGPU(同一の消費電力、メモリ容量・ブロワータイプ)で取得した結果となります。

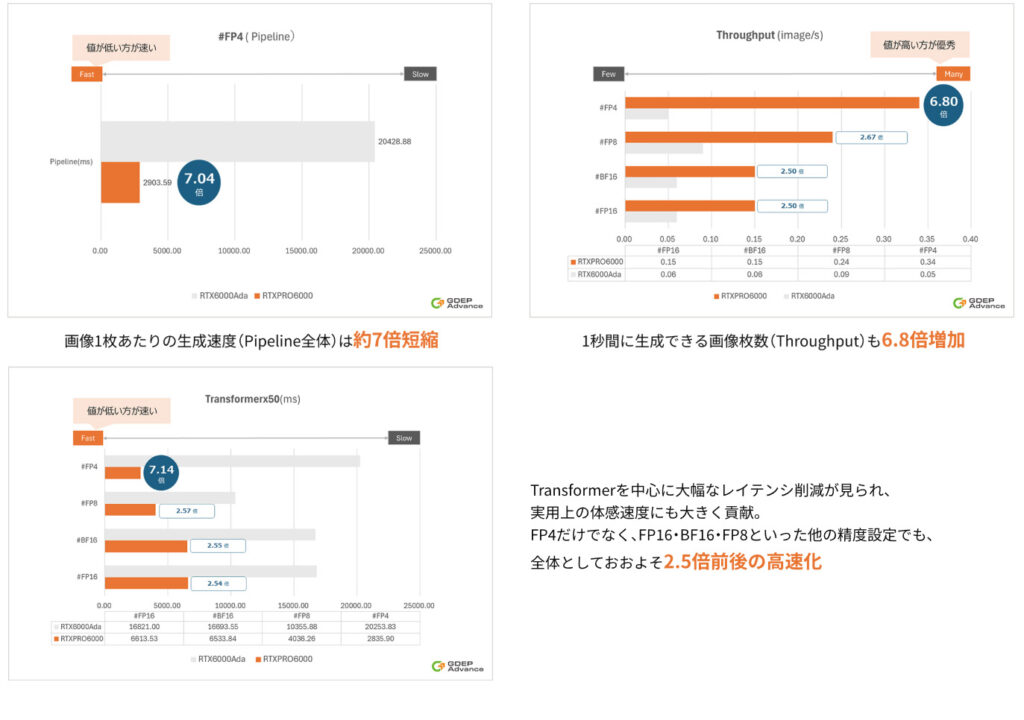
Blackwell世代では、第5世代Tensor CoreによるFP4およびFP6演算が新たに正式サポートされました。
これにより、従来よりもはるかに低い精度での高速かつ効率的な推論が可能となりました。
さらに、TensorRT 10.0以降では、Blackwell世代以降のGPUにおいてFP4(軽量な演算精度)が
行列演算で正式にサポートされたため、推論処理全体の高速化が実現しています。
また、96GBのGDDR7メモリと1.8TB/sのメモリ帯域幅により、大規模な生成AIモデルでも安定して高速な処理が可能です。
※この結果は2024年7月時点で入手可能なドライバーやCUDA、学習モデルの最新バージョンを用いたものであり、
今後ソフトウェアのバージョンアップ等により性能値が変化する場合がありますことをご了承下さい。


