search製品名・スペックから検索






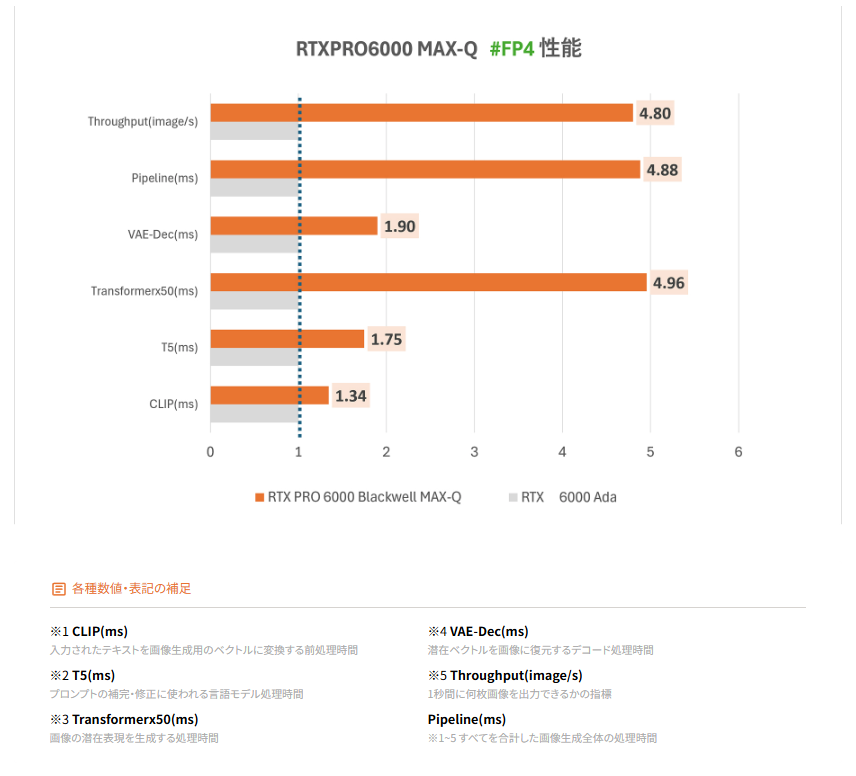
RTX 6000Ada と RTX PRO 6000 Blackwell Max-Qの画像生成における推論速度を比較ベンチマーク
NVIDIA RTX 6000Ada と RTX PRO 6000 Blackwell Max-Qを用いて、
画像生成における推論速度を比較
NVIDIAのBlackwell世代では、4ビット浮動小数点(FP4)精度の量子化対応が正式にサポートされ、従来よりもはるかに低い精度での高速かつ効率的な推論が可能となりました。
これにより、特に画像生成タスクにおける処理速度と精度が著しく向上しました。
システム要件
ベンチマーク機種:DeepLearningBOXⅢ
GPU:GPUはそれぞれ1基
CPU:1x Intel Xeon w7-3565X
マザーボード:ASUS-PRO/WS/W790E-SAGE/SE (Intel W790 チップセット)
MEM:128GB DDR5-4800 ECC
ストレージ:M.2 NVMe SSD 1TB
電源:HX1500i × 2
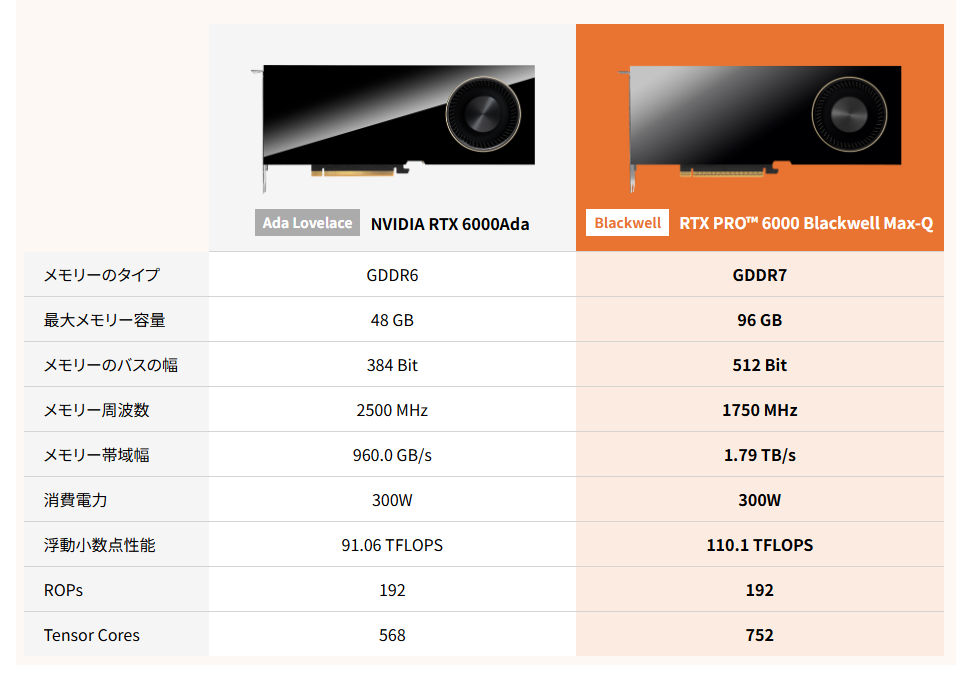
NVIDIA RTX 6000Ada / RTX PRO 6000 Blackwell Max-Qの仕様

最適化により、画像生成のように複数の重い処理を連続して行うタスクで特に効果を発揮。
Blackwell世代のGPUは、AI推論における新たな基準を確立し、
より高速で効率的な処理を実現しました。
transformerを中心に大幅なレイテンシ削減が見られ、実用上の体感速度にも大きく貢献しています。
また、FP4だけでなく、FP16・BF16・FP8といった他の精度設定でも、全体として約1.7倍前後の高速化が確認されました。
TensorRT 10.0以降では、Blackwell世代以降のGPUでFP4という軽量な演算精度が行列演算で正式にサポートされており、これが
推論処理全体の高速化につながっています。96 GBのGDDR7メモリと1.8 TB/sのメモリ帯域により、大規模な生成AIモデルでも
安定して高速な処理が可能です。