
ファインチューニング性能比較ベンチマーク
8B LoRA スループット
70B QLoRA スループット
70B 学習時間の短縮
※ 数値は当社検証環境(2026年6月)での実測値です。条件はページ下部「検証条件」をご確認ください。
LoRA・QLoRA 検証
ベンチマーク取得の背景
生成AIやLLMのファインチューニングでは、学習・評価・改善を繰り返しながら、未知のデータにも高い性能を発揮するAIモデルへと育てていきます。そのため、1回の学習速度だけでなく、限られた時間でどれだけ多くの検証サイクルを回せるかが、開発効率やAIモデルの品質を大きく左右します。
また、LLMを自社データでカスタマイズするファインチューニングでは、GPUのVRAM容量と演算性能が重要な要素となります。
そこで本ベンチマークでは、Llama 3.1 8B / 70Bを用いたLoRA・QLoRAによるファインチューニングを実施し、NVIDIA RTX PRO 6000 Blackwell Max-QとRTX 6000 Adaの実アプリケーション性能を比較しました。大規模LLMのファインチューニングにおけるMax-Qの優位性を検証しています。
※本文中の専門用語は、ページ下部の「用語説明」でわかりやすく解説しています。
比較対象のGPU
GPU以外はすべて同一構成で、この2機種を比較しました。


| 項目 | RTX 6000 Ada | RTX PRO 6000 Blackwell Max-Q |
|---|---|---|
| アーキテクチャ | Ada Lovelace | Blackwell |
| CUDAコア数 | 18,176 | 24,064 |
| Tensorコア | 568基(第4世代) | 752基(第5世代) |
| メモリタイプ | GDDR6 | GDDR7 |
| VRAM(最大メモリ容量) | 48GB | 96GB |
| メモリバス幅 | 384 bit | 512 bit |
| メモリ周波数 | 2,500 MHz | 1,750 MHz |
| メモリ帯域幅 | 960 GB/s | 1,792 GB/s |
| 単精度演算性能 | 91.1 TFLOPS | 110 TFLOPS |
| ROPs | 192 | 192 |
| システムインタフェース | PCIe 4.0 | PCIe 5.0 |
| 消費電力 | 300W | 300W |
検証結果
今回の検証では、RTX PRO 6000 Blackwell Max-Q は RTX 6000 Ada と比較し、Llama-3.1-8B では実務的なバッチサイズ(BS4〜BS8)で最大約86%、Llama-3.1-70B では最大約107%(約2.1倍)のスループット向上を確認しました。70B モデルでは VRAM 使用量が両GPUでほぼ同等(約45〜46GB)であるにもかかわらず実アプリケーション性能に大きな差が見られ、Blackwell 世代で強化された第5世代 Tensor Core や GDDR7 メモリサブシステムなどのアーキテクチャ改善が、ファインチューニング性能の向上に寄与していることを示しています。GPU以外はすべて同一構成で比較しており、公平な条件で Blackwell 世代の性能向上を実証しています。
70B の QLoRA でパフォーマンスを発揮
RTX 6000 Ada を基準(1.0倍)とした、ファインチューニング・スループットの高速化倍率。
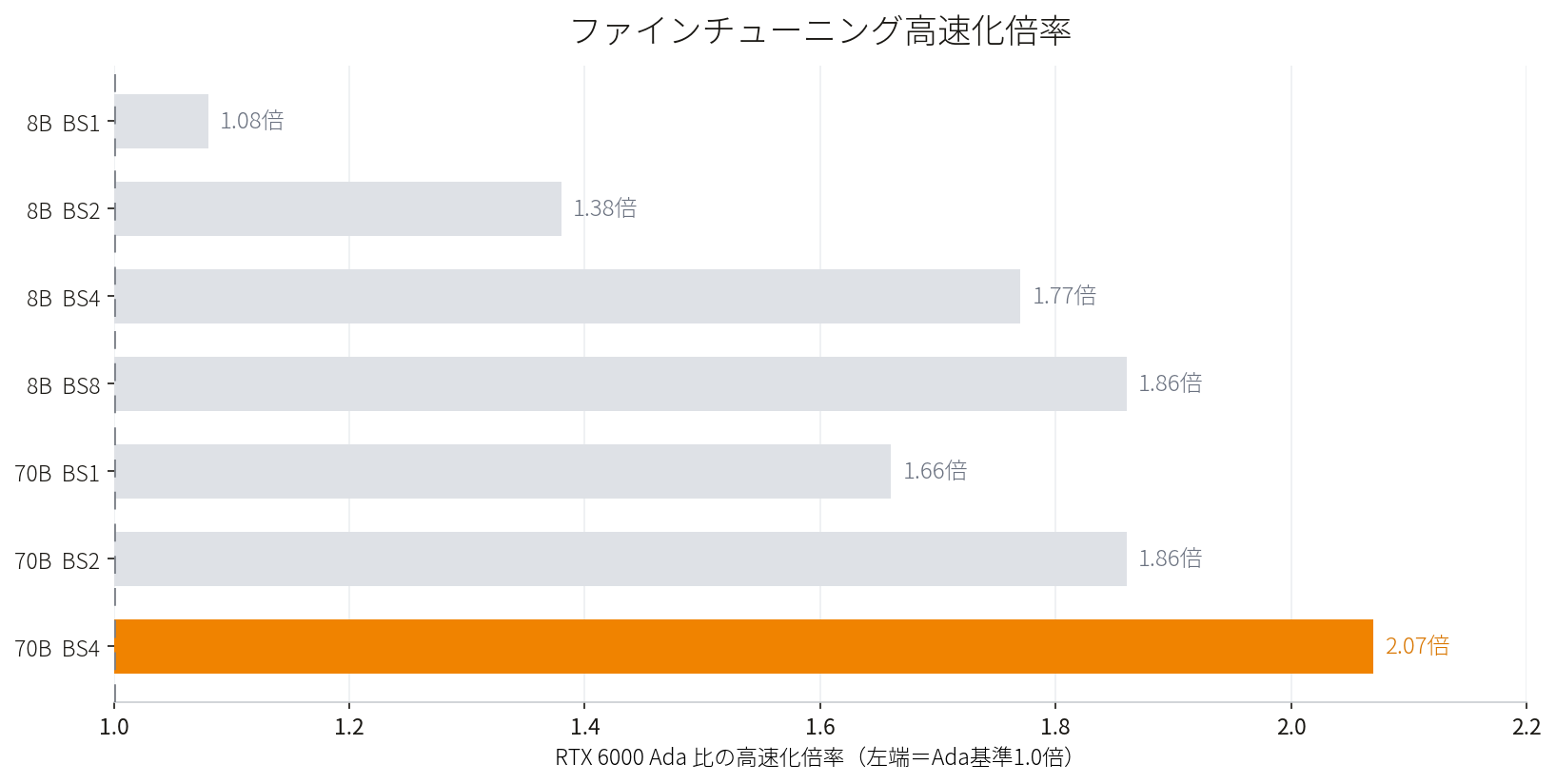
小規模な学習では、両モデルとも快適に動作。真価が発揮されるのは、大規模なモデルを一度に多くのデータで学習させるような負荷の高い場面です。一方で、70B QLoRAのようにモデル規模やバッチサイズが大きい条件では、Adaに対するMax-Qの優位が拡大し、今回の検証では最大約2.1倍のスループットを確認しました。学習負荷が高い条件ほど、Max-Qのアーキテクチャ差が表れやすい傾向があります。
1.08倍 → 2.07倍学習の規模を大きくするほど差が拡大。
Llama-3.1 スループット推移比較
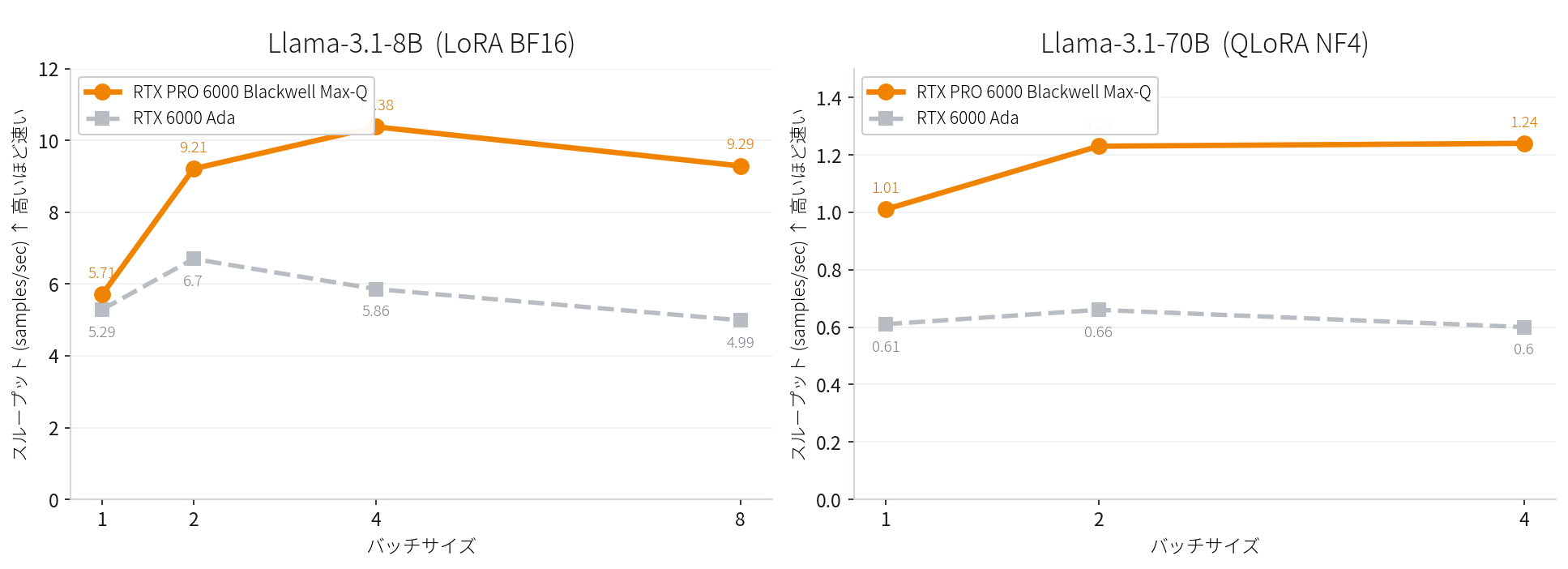
8BモデルLlama-3.1-8B / LoRA BF16
両GPUともに動作しましたが、バッチサイズを上げるほどスループットの差が広がりました。バッチサイズ1ではほぼ同等でしたが、バッチサイズ4では Max-Q が Ada の約1.77倍、バッチサイズ8では約1.86倍のスループットを記録しました。また Ada はバッチサイズ2でスループットが頭打ちになったのに対し、Max-Q はバッチサイズ4まで伸び続けました。
GPUの演算性能の差は、負荷が高まるほど顕在化する傾向があります。実務的なバッチサイズで使うほど、その差が出やすくなります。
70BモデルLlama-3.1-70B / QLoRA NF4
バッチサイズ1では Max-Q が Ada の約1.66倍、バッチサイズ2では約1.86倍、バッチサイズ4では約2.07倍と、バッチサイズが上がるほどスループットの差が広がりました。また VRAM の観点では、両GPUとも45〜46GB程度の使用量でほぼ同等でしたが、スループットには2倍以上の差が出ました。
70Bクラスのモデルになると、VRAM使用量が拮抗していてもスループットに大きな差が生じることが確認できました。これはメモリ容量だけでなく演算性能そのものの差が直接影響していると考えられます。今後さらに大規模なモデルの活用を視野に入れるのであれば、VRAMの余裕は無視できない要素になってくると考えられます。
学習時間
Llama-3.1-70B QLoRA(BS4)における1エポックの学習時間
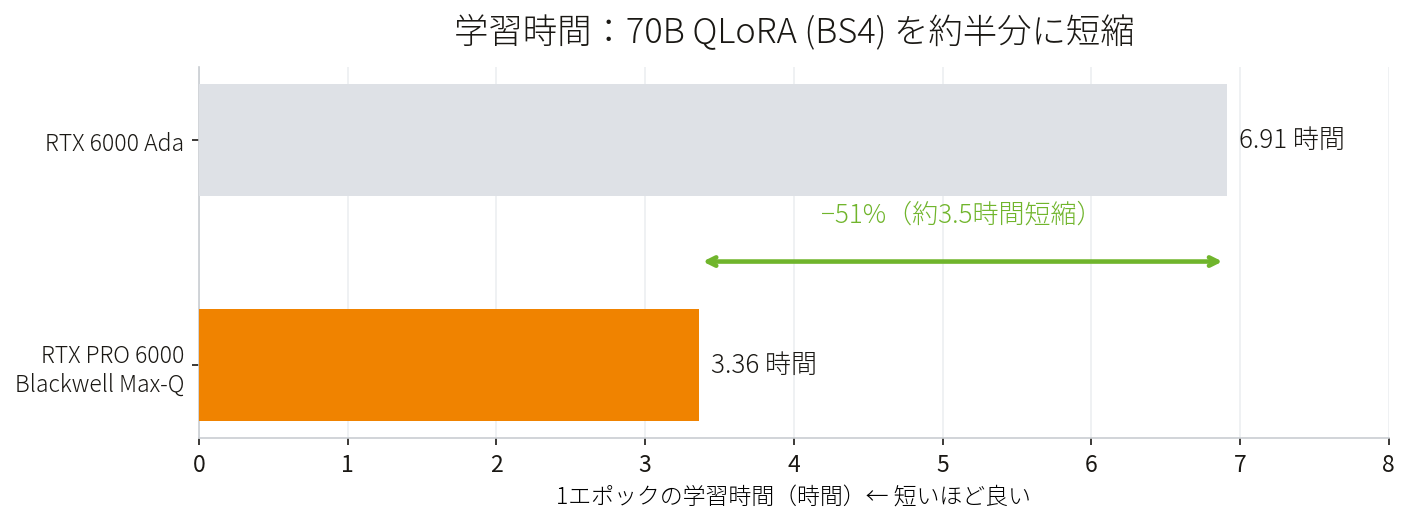
6.91h → 3.36h1回の学習が約半分に。同じ時間で2倍の試行回数を回せるため、モデル改善のスピードが上がり、研究者の時間コストも削減できます。
マルチGPU構成なら、更にパフォーマンスを発揮(理論値)
単一GPUでも約半分に短縮した学習時間は、マルチGPU構成でさらに時間短縮できます。
※ 以下は 70B QLoRA(BS4) の単一GPU実測値(約3.36時間)を起点に、スケーリング効率90%を仮定した理論上の試算です。実測値ではなく、構成・ネットワーク・並列手法により変動します。
| GPU数 | 予想学習時間 | 性能向上(対1GPU) |
|---|---|---|
| 1 GPU | 約3.36時間(実測) | 1.0倍 |
| 2 GPU | 約1.9時間 | 約1.8倍 |
| 4 GPU | 約0.9時間 | 約3.6倍 |
GPUを増やすほど、1日に回せる学習・評価サイクルは大きく増加します。大規模な学習・PoC を短期間で反復できることが、マルチGPU構成の最大のメリットです。
Tensor Core・GDDR7・大容量VRAMによる性能向上
この性能差は、Blackwell 世代のメモリサブシステムと Tensor Core の改善によるものです。
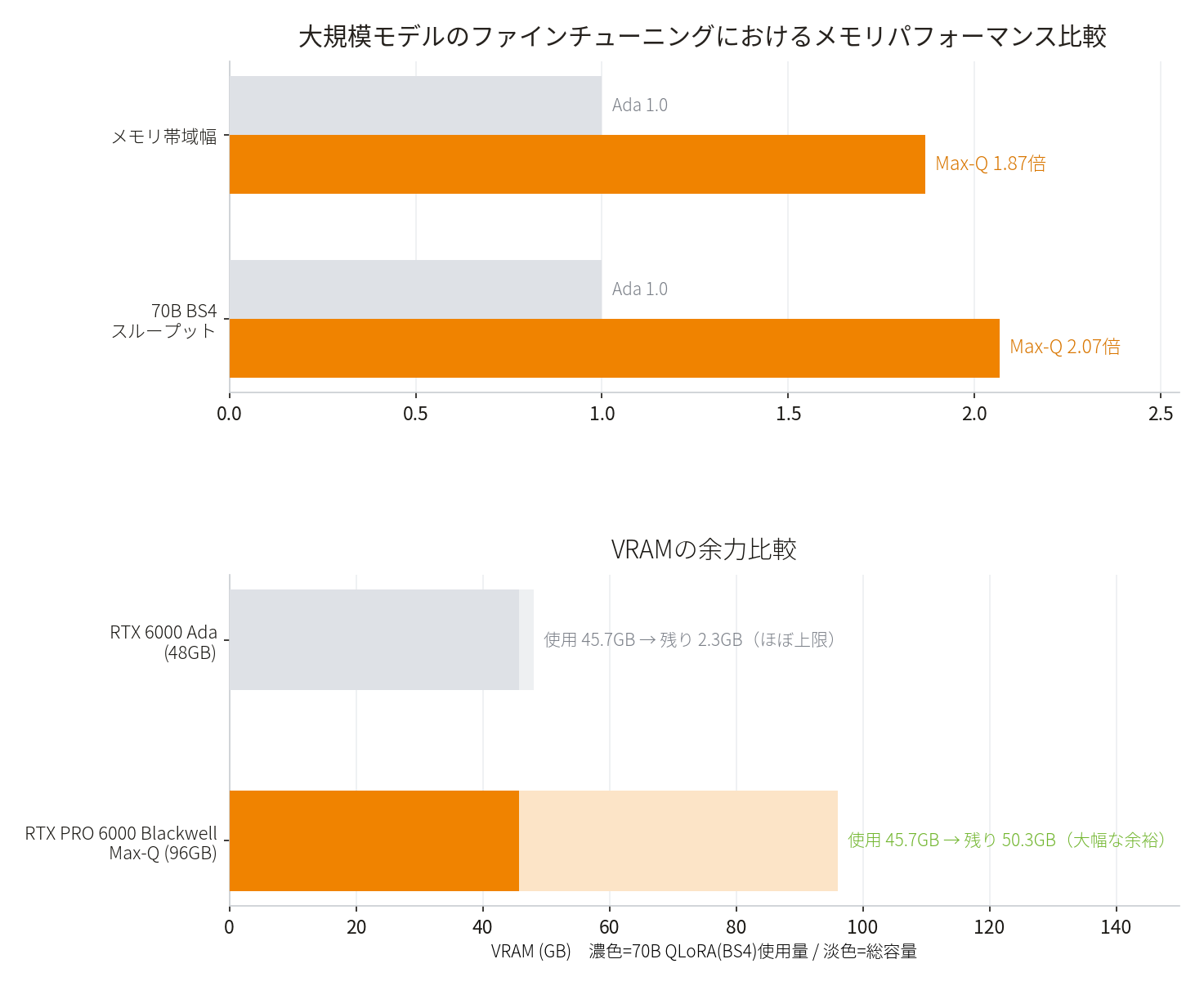
大規模モデルのファインチューニングはメモリ帯域幅が律速となります。70BモデルではVRAM使用量が両GPUで近い条件でも、スループットに約2倍の差が見られました。この性能向上は、Blackwell世代で強化されたTensor Core、GDDR7メモリサブシステム、96GBの大容量VRAMが複合的に支えています。
さらに96GBの大容量VRAMは、「できることの幅」も広げます。70B QLoRA(BS4)においてもVRAMに余力を確保できるため、バッチサイズの拡大、より長いシーケンス長への対応、複数条件での検証など、オンプレミスでの実用的なファインチューニング運用に対応しやすくなります。
注目ポイントメモリ帯域幅のスペック差に近いレンジで、実測スループットも向上
ファインチューニングのワークロードは、メモリ帯域幅が性能に影響しやすい傾向があります。今回の検証では、メモリ帯域幅が約1.87倍に向上したのに対し、8B バッチサイズ8では約1.86倍、70B バッチサイズ4では約2.07倍のスループット向上を確認しました。スペック上の帯域差に近いレンジで実性能が伸びており、GDDR7メモリサブシステムの強化が実アプリケーション性能にも表れています。
総評
8Bと70Bのいずれのモデルにおいても、Max-Q は Ada を上回るスループットを記録しました。特にバッチサイズや扱うモデルの規模が大きくなるほどその差は顕著になる傾向があり、大規模なモデルを実務で継続的に活用していく上では、VRAMの余裕を含めたGPU性能が重要な選定基準になると考えられます。
検証条件
本検証は、オンプレミス環境でのLLMファインチューニング運用を想定し、当社検証環境で実施したものです。8BモデルではLoRA、70BモデルではQLoRAを使用し、同一条件下でRTX 6000 AdaとRTX PRO 6000 Blackwell Max-Qを比較しています。掲載値は特定条件下での実測値であり、モデル、データセット、シーケンス長、バッチサイズ、ソフトウェア構成により変動します。
検証概要(前提条件)
| 比較GPU | NVIDIA RTX 6000 Ada / NVIDIA RTX PRO 6000 Blackwell Max-Q |
|---|---|
| 対象モデル | Llama 3.1 8B Instruct / Llama 3.1 70B Instruct |
| 学習方式 | 8B:LoRA BF16、70B:QLoRA NF4 |
| データセット | 日本語instructionデータ 約15,000件 |
| 学習条件 | 1 epoch、max sequence length 512 |
| 測定指標 | 学習スループット samples/sec、学習時間 |
| 検証環境 | 同一オンプレミス検証環境で比較 |
| 備考 | FlashAttentionおよびFP8は未使用 |

当社のAIワークステーションでもパフォーマンスを発揮
当社のAIワークステーションは、RTX PRO 6000 Blackwell Max-Qを最大4基搭載可能な高い拡張性と、約30dBクラスの静音設計、サーバー製品では最大8GPUによる学習時間の短縮や大規模AIモデルへの対応、複数ジョブの並列実行まで幅広いAIワークロードを支え、PoCから研究開発、本番運用まで、お客様のAI開発を加速する高性能AIプラットフォームを提供します。



