
革新的AI処理力&ビジュアル性能

次世代データセンターに最適化された
NVIDIA RTX PRO™ 6000 Blackwell Server Editionで
マルチワークロードをスマートに高速化
NVIDIA RTX PRO™ 6000
Blackwell Server Edition とは?

複雑なタスクを、シンプルに解決
RTX PRO 6000 Blackwell Server Editionは、マルチGPUサーバー向けに設計された高性能GPUです。
パッシブ冷却を採用し、エネルギー効率とパフォーマンスのバランスを最適化。推論、ファインチューニング、分散レンダリング、HPC、仮想ワークステーションなど、エンタープライズデータセンターの多様なワークロードに対応し、強力なパフォーマンスと多様なコンピューティング機能でビジネスの生産性を高めます。
最新のRTX PRO 6000 Blackwell Server Editionで
エンタープライズ
AI ファクトリーを構築
AI ファクトリーは、生成 AI やシミュレーション、ロボティクス、デジタルツインなどの多様な研究開発・産業用途に対応し、
あらゆる AI ワークロードを高性能かつスケーラブルに処理できるよう設計された統合基盤です。
AIエージェント
動画や画像の作成

デジタルツイン
ゲノムと創薬開発

レコメンド

コンテンツ作成

ロボティクス
データサイエンス
と解析
ライブメディア

バーチャル
ワークス
テーション
ワークロードパフォーマンス






LLama3 70B 推論;8K/256、20 トークン/秒/ユーザー、2秒 FTL、8 GPU;RTX PRO 6000 (FP4) 対 L40S (FP8)
DLRM(20ms レイテンシ);サンプル数/秒;RTX PRO 6000 対 L40S (INT8)
Cosmos-1.0-Diffusion-7B-Text2World;2.5秒 720p ビデオ、画像数/秒、64 GPU;RTX PRO 6000 (FP4) 対 L40S (FP8)
Smith & Waterman(TCUPs);8ビット;RTX PRO 6000 対 L40S
LSS4搭載オムニバース;RTX PRO 6000 対 L40S
DLSS4搭載4Kゲーミング(RTX + AI);RTX PRO 6000 対 L40S

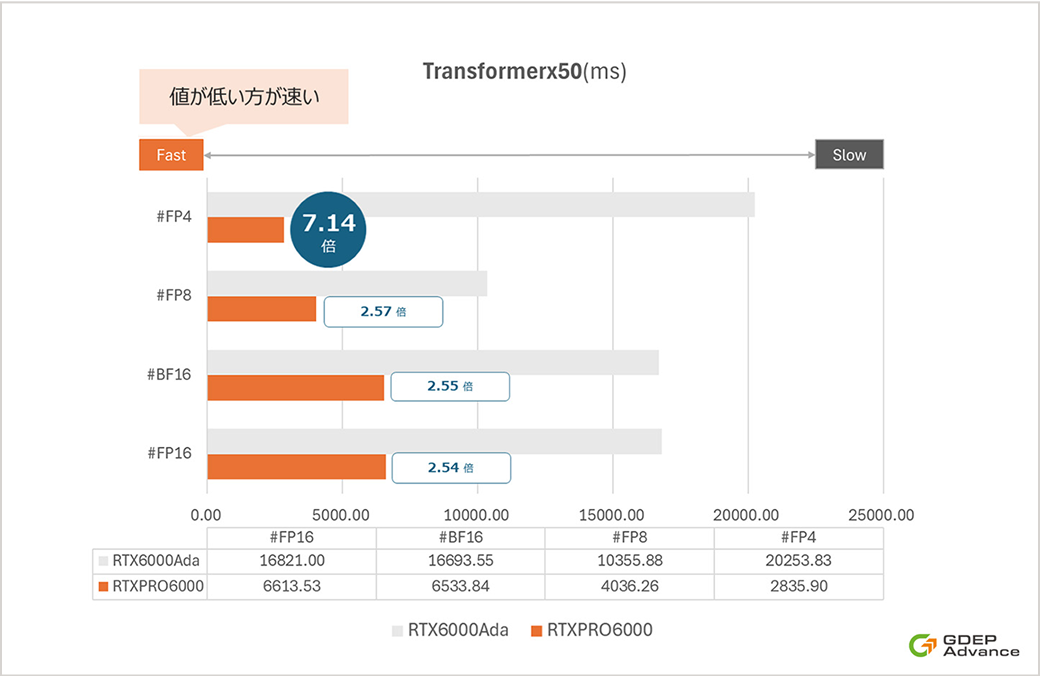
RTX 6000Ada比の速度倍率
ベンチマークレポート
最適化により画像生成のように
複数の重い処理を連続して
行うタスクで特に効果を発揮
GDEP
ベンチマークデータ
NVIDIA社提供の
ベンチマークデータ
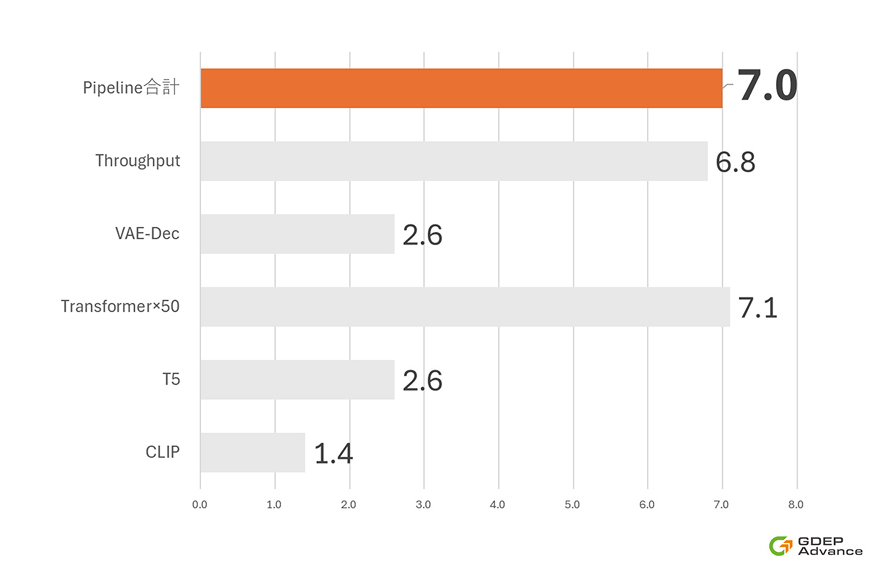
モジュール別およびパイプライン全体における
推論速度の比較結果
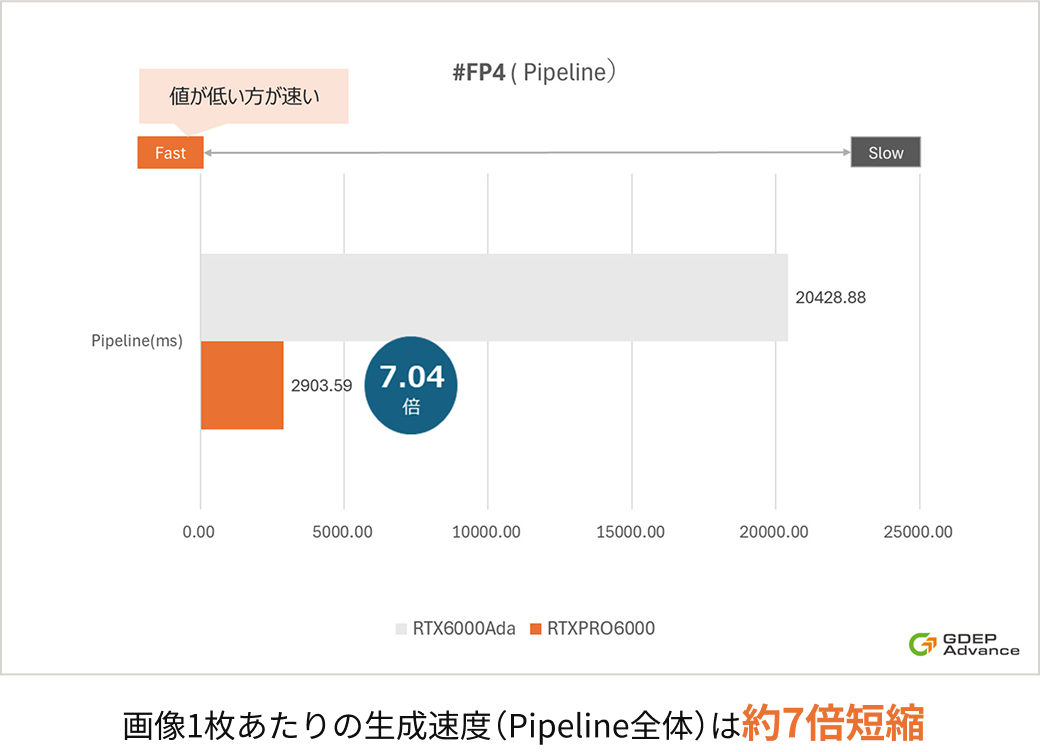
GitHub 上で公開されているTensorRT 10.11 デモ環境(Diffusion Pipeline)をベースに、
NVIDIA RTX™ 6000AdaとNVIDIA RTX PRO™ 6000 Blackwell Workstation Editionを用いて画像生成における推論速度を
当社の環境で比較ベンチマークを取得しました。
その結果、画像1枚あたりの生成時間(Pipeline全体)がNVIDIA RTX™ 6000Adaと比較して、
約7倍高速化されました。
※同シリーズの別型番のGPU(同一の消費電力、メモリ容量・ブロワータイプ)で取得した結果となります。
REPORT
RTX 6000Ada比のモジュール別速度倍率は約7倍高速化。

各種数値・表記の補足
※1 CLIP(ms)
入力されたテキストを画像生成用のベクトルに変換する前処理時間
※2 T5(ms)
プロンプトの補完・修正に使われる言語モデル処理時間
※3 Transformerx50(ms)
画像の潜在表現を生成する処理時間
※4 VAE-Dec(ms)
潜在ベクトルを画像に復元するデコード処理時間
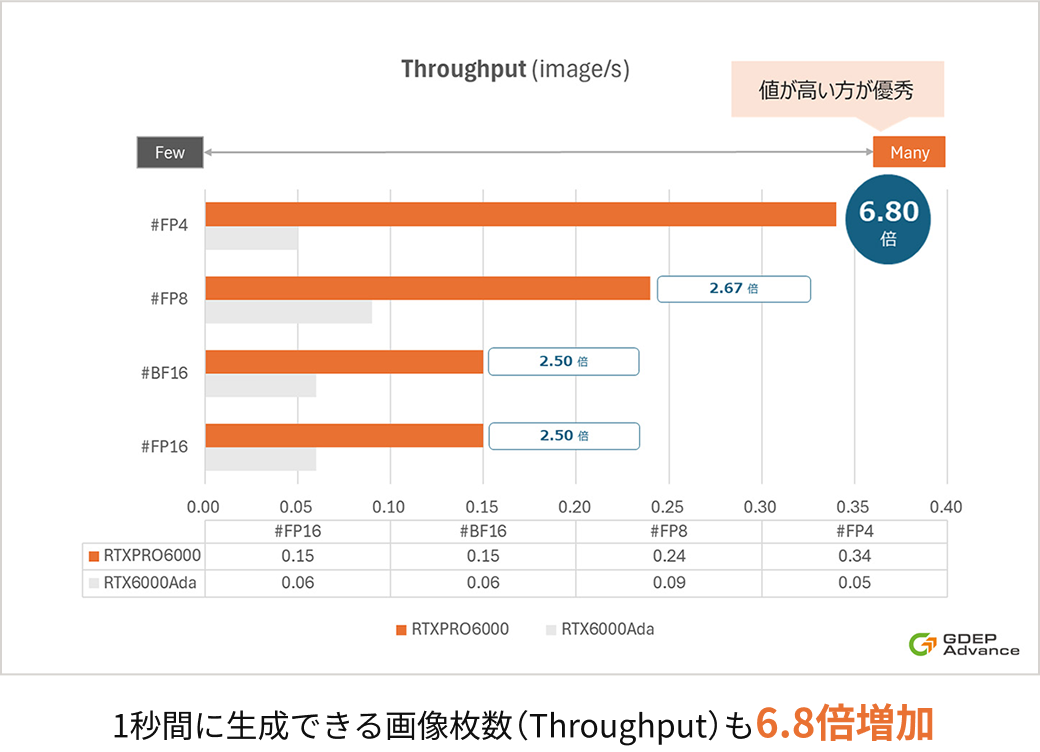
※5 Throughput(image/s)
1秒間に何枚画像を出力できるかの指標
Pipeline(ms)
※1~5 すべてを合計した画像生成全体の処理時間
FP4において実力を発揮
Blackwell世代では、第5世代Tensor CoreによるFP4およびFP6演算が新たに正式サポートされました。
これにより、従来よりもはるかに低い精度での高速かつ効率的な推論が可能となりました。
さらに、TensorRT 10.0以降では、Blackwell世代以降のGPUにおいてFP4(軽量な演算精度)が
行列演算で正式にサポートされたため、推論処理全体の高速化が実現しています。
また、96GBのGDDR7メモリと1.8TB/sのメモリ帯域幅により、大規模な生成AIモデルでも安定して高速な処理が可能です。

※この結果は2024年7月時点で入手可能なドライバーやCUDA、学習モデルの最新バージョンを用いたものであり、
今後ソフトウェアのバージョンアップ等により性能値が変化する場合がありますことをご了承下さい。
LLM推論とファインチューニング
前モデルL40Sと比較したRTX PRO 6000 Blackwell Server Editionの
小規模から中規模のモデルのパフォーマンス
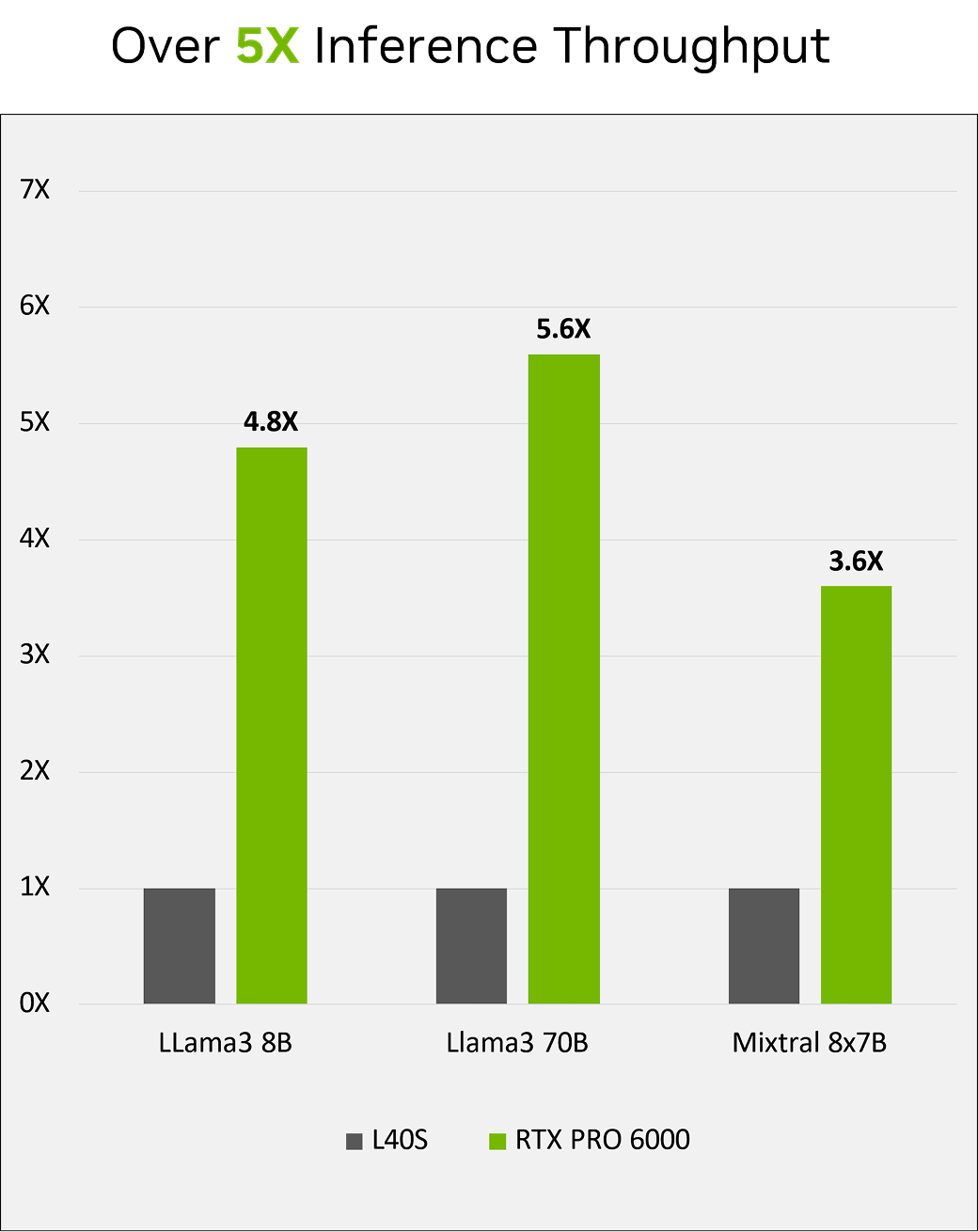
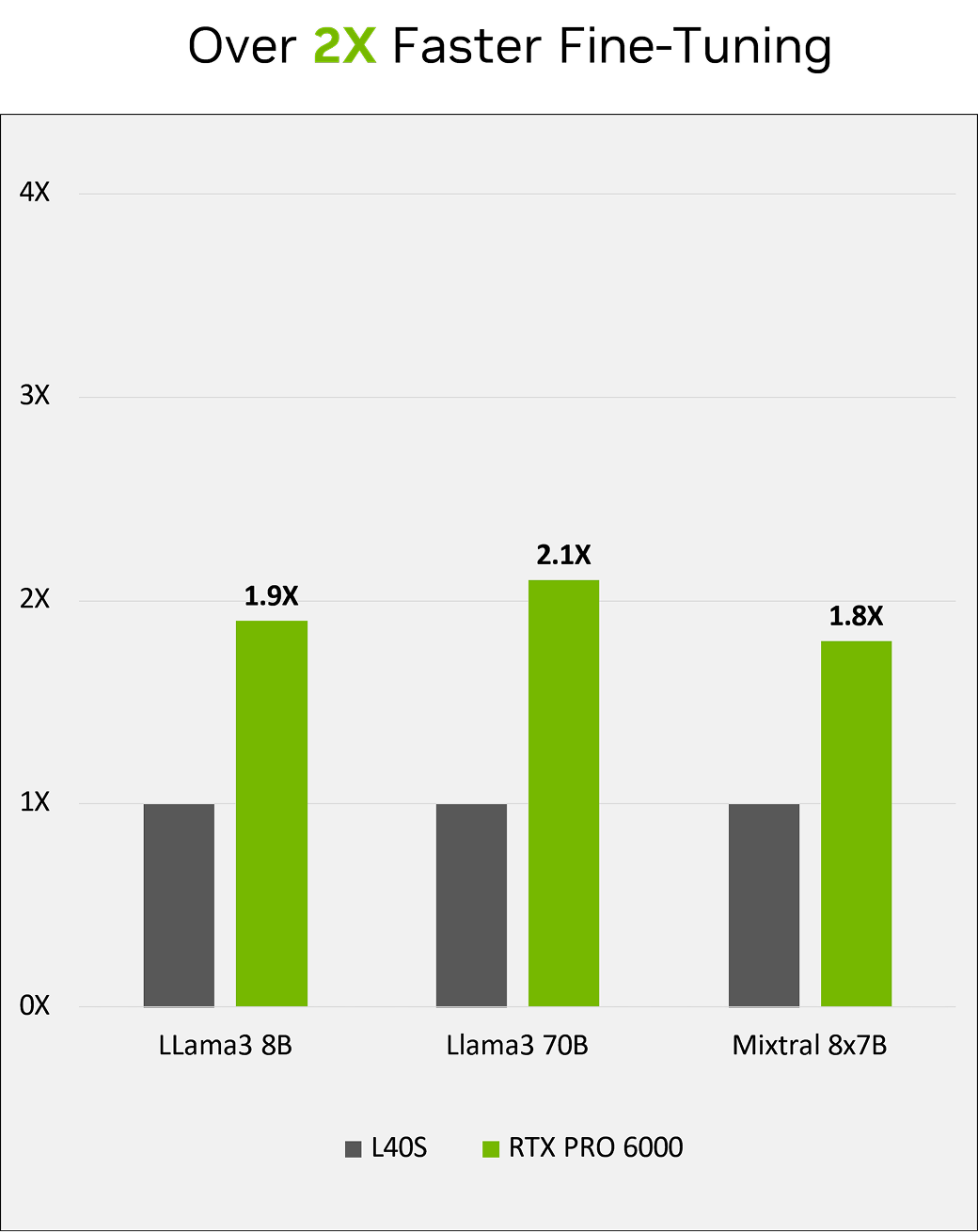
特に高いパフォーマンスを発揮する領域
前モデルL40Sと比較したRTX PRO 6000 Blackwell Server Editionの
小規模から中規模のモデルのパフォーマンス(NVIDIA社提供)
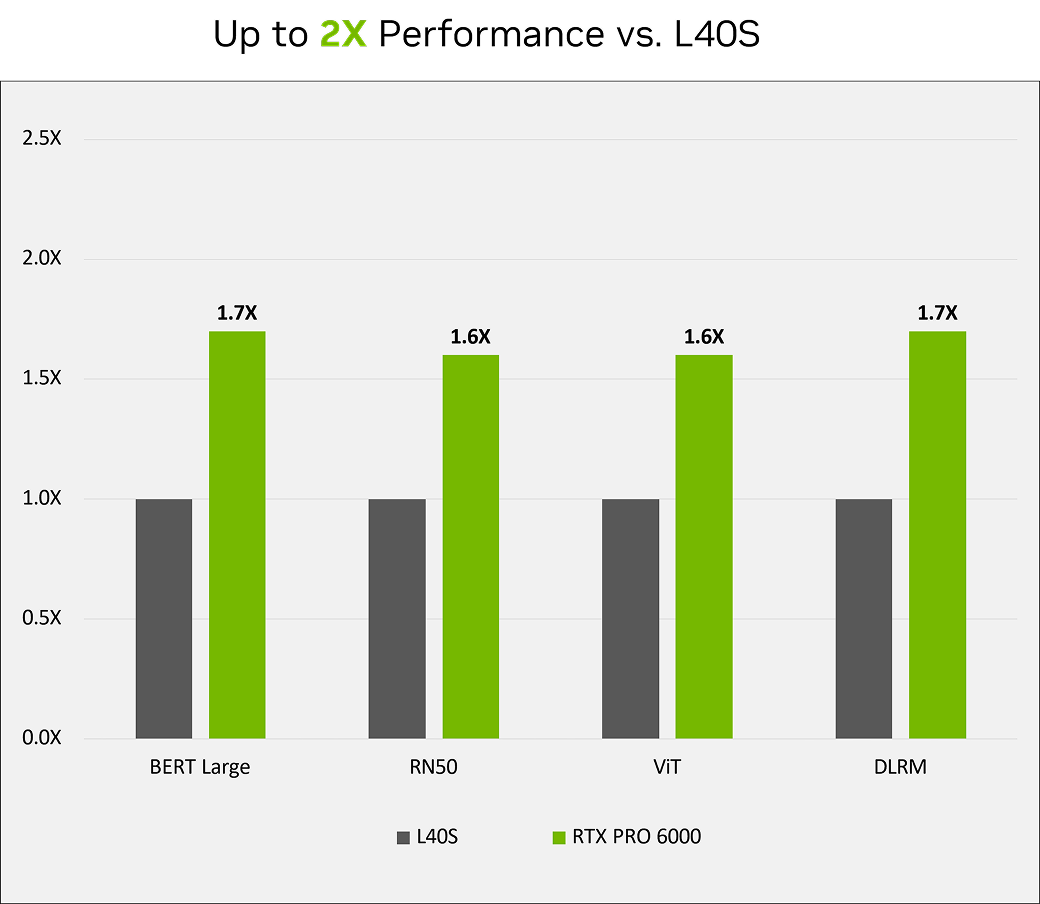
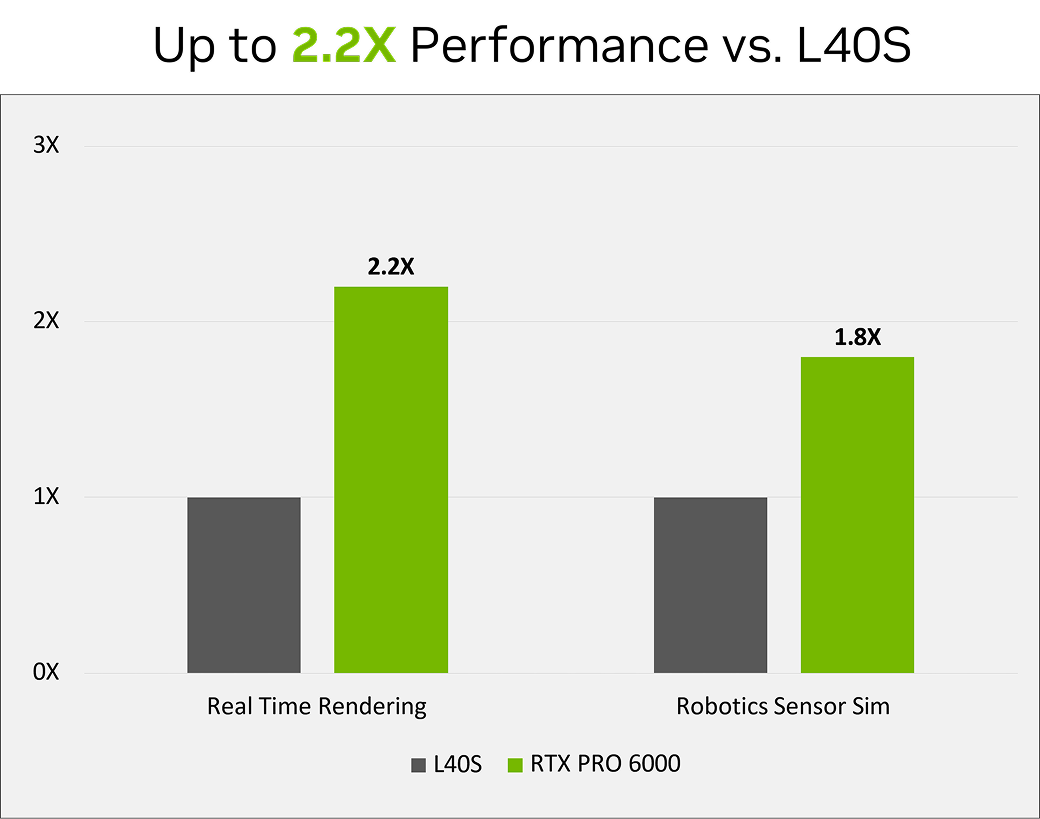
特に高いパフォーマンスを発揮する領域
RTX PRO 6000 Blackwell Server Editionの
パフォーマンスを
最大限発揮できるシステム
NVIDIA RTX PRO 6000 Blackwell Server Edition を搭載した「NVIDIA RTX PROサーバー」は、最新のNVIDIA Blackwellアーキテクチャを使って、高いパフォーマンスとエネルギー効率を実現しあらゆるエンタープライズ ワークロードを加速。
AI技術を活用した工場(AIファクトリー)や、研究開発領域においての
さまざまなタスクを高いパフォーマンスで処理できる設計に最適化。


RTX PRO 6000 Server Editionと
他製品の構成・仕様比較
それぞれの仕様と強み、特徴の傾向など、検討時に押さえておきたい要素をまとめました。
製品選びの参考としてぜひご活用ください。
| RTX PRO 6000 Server Edition | HGX Server | |
|---|---|---|
| 搭載GPU | RTX PRO 6000 Blackwell Server Edition | HGX-B200 |
| コスト |
|
|
| GPUのカスタマイズ性 |
1枚ずつ予算や利用用途に合わせて増設が可能 PCI |
8基固定 SXM |
| 拡張性 |
NVIDIA BlueField®-3に対応
高速・広帯域ネットワークカード専用スロットを装備しており、マルチノードでのクラスター構築も可能。 |
NVSwitchテクノロジーを広範に採用し、優れたスケーラビリティを備えたGPUインターコネクトを提供。
データセンターレベルの大規模なマルチノードAIまたはHPCクラスターの構築に最適。 |
| 強み | AI アクセラレーションワークロードでの多様な要件に対応可能。 PCI Express対応GPUのため、予算や目的に応じて GPU搭載数を1基から8基まで選択可能。 |
クラウドやデータセンター環境での大規模AI処理や マルチユーザー対応に圧倒的なパフォーマンスを発揮し、 スケーラビリティやネットワーク統合性にも優れている。 |
RTX PRO Server
GSV-IGRAS-4U8G
エンタープライズ向け
PCIe構成ユニバーサル
データセンタープラットフォーム
NVIDIA MGX
2CPU
4U Rackmount
8GPU
NVMe
PCIe 5.0
DDR5
80 PLUS Titanium
製品の特長
- インテル® Xeon® 6デュアルプロセッサーを2CPU(最大172コア)搭載
- メモリ:最大4TB DDR5 6400MT/s ECC RDIMM (1DPC) / 5200 (2DPC)
- 高密度4Uコンピューティングサーバーに2スロットGPUを8基搭載
- 広帯域のPCIe 5.0とスケーラブルなNVMeストレージを最適化
※GPUあたり各600wまで対応 - GPUに最適化した熱設計専用エアフロー
- 簡単かつ柔軟に拡張可能MGXアーキテクチャ
複数の構成を可能にするモジュール設計 - 電源:冗長(3+1)合計4基の3200W 80 PLUS Titanium
RTX PRO Server
GSV-ATRSM-5U8G
5Uラック・高性能ファン10基設計により安定した
エアフローを維持
大規模HPCに最適なパフォーマンス
LGA 4710
2CPU
5U Rackmount
8GPU
NVMe
PCIe 5.0
DDR5
80 PLUS Titanium
製品の特長
- プロセッサー:AMD EPYC™ 9005シリーズデュアルプロセッサー(最大192コア)
- メモリ:最大6TB DDR5 6400MT/s ECC RDIMM (1DPC)
- 2スロットGPUを最大8基搭載
- 最大24基のDIMM、6400 MT/s 6TB DDR5 を 1DPC でサポート
- 9つのPCIe 5.0 x16 FHFLスロット
- 2つのフロントホットスワップ対応2.5インチSATA
+ 4つのフロントホットスワップ対応2.5インチNVMeドライブベイ - 電源:冗長(3+3)合計6基の2700W Titanium Level (96%)
※電源ユニットの完全冗長化は構成とアプリケーション負荷に依存