
DGX Station(GWS-GB300SM)
NVIDIA GB300 Grace Blackwell Ultra Desktop Superchip 搭載
NVIDIA DGX™ Station
GWS-GB300SM
デスクサイドに置ける、Direct-to-Chip 水冷のAIワークステーション。

⚡ 電源要件デスクサイドに設置可能ですが、動作には単相200V電源を推奨します
NVIDIA GB300 Grace™ Blackwell Ultra デスクトップ スーパーチップを搭載生成AI・推論ワークロードに最適化した
水冷式AIワークステーション
NVIDIA GB300 スーパーチップと、Supermicro のエンタープライズ・サーバー設計を組み合わせた、ローカルAI開発のための1台です。

GB300 スーパーチップ搭載
72コア Grace ARM CPU と Blackwell B300 GPU(252GB HBM3e)を1チップに統合。FP4で最大20 PFLOPS、最大1兆パラメータ級のモデルに対応します。
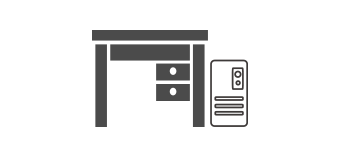
デスクサイドに置けるサイズ
データセンターを必要とせず、5Uタワー筐体でラボやオフィスのデスクサイドに設置可能。設置場所を選ばず、手元で大規模AIを動かせます。
⚡ 電源要件単相200V電源を推奨します。

Direct-to-Chip 閉ループ水冷
GPU・CPUを直接冷やす Direct-to-Chip(D2C)方式の閉ループ液冷を採用。施設側の水冷設備を必要としない自己完結型で、高TDPのGB300でもサーマルスロットリングを抑え、持続的な性能を発揮します。

サーバー譲りの信頼性
GB300 NVL72 などのAIサーバーで実績を持つSupermicroの設計を継承。ワークステーションを超える稼働率とサービス性で、本番ワークロードを支えます。
400GbE×2 で拡張も視野に
オンボードの ConnectX-8 SuperNIC により最大800Gb/sのネットワーク。マルチノード構成やデータセンターへの直接統合へ、スムーズに拡張できます。

すぐ使える開発環境
Ubuntu 24.04 と NVIDIA AI Developer Tools をプリインストール。CUDA-X や各種フレームワークをダウンロードして、届いたその日から開発を始められます。
1チップあたりの性能が、業界最高クラス
GPUメモリ容量・対応モデル規模・AI演算性能を、主要GPUとチップ単位で比較しました。
GPU Memory per Chip
1チップあたりのGPUメモリ容量(GB)
Max LLM Size per GPU
1GPUで対応可能なLLM規模の目安(10億パラメータ単位)
AI PetaFLOPS — Chip to Chip
チップ単位のAI演算性能(各GPUで最も低いFP精度で比較)
※ 各GPUで利用可能な最小FP精度(FP4 / FP8 / FP16)での比較値です。
GPU製品ラインナップ仕様
最新のGB300(オレンジの箇所)以外にも用途に応じて、データセンター規模のGPU まで幅広くご提案します。
| 仕様 | NVIDIA GB300 |
NVIDIA H200 NVL |
NVIDIA HGX B200 |
NVIDIA HGX B300 |
|---|---|---|---|---|
| 製品画像 |  |
 |
 |
 |
| フォームファクター | Grace Blackwell | PCIe デュアルスロット空冷 | 8× Blackwell SXM | 8× Blackwell Ultra SXM |
| FP64 / FP64 Tensor コア | 1.3 TFLOPS | 30 / 60 TFLOPS | 296 TFLOPS | 10 TFLOPS |
| FP32 | 80 TFLOPS | 60 TFLOPS | 600 TFLOPS | 600 TFLOPS |
| TF32 Tensor コア * | 2.5 PFLOPS | 835 TFLOPS | 18 PFLOPS | 18 PFLOPS |
| FP16 / BF16 Tensor コア * | 5 PFLOPS | 1,671 TFLOPS | 36 PFLOPS | 36 PFLOPS |
| FP8 / FP6 Tensor コア * | 10 PFLOPS | 3,341 TFLOPS | 72 PFLOPS | 72 PFLOPS |
| FP4 Tensor コア ** | 20 | 15 PFLOPS | — | 144 | 72 PFLOPS | 144 | 105 PFLOPS |
| INT8 Tensor コア * | 330 PFLOPS | 3,341 TFLOPS | 72 PFLOPS | 2 PFLOPS |
| メモリ | GPU 252GB / CPU 496GB | 141 GB | 1.4 TB | 最大 2.3 TB |
| メモリ帯域 | GPU 7.1TB/s / CPU 396GB/s | 4.8 TB/s | — | — |
| NVLink 帯域幅 | NVLink-C2C 900 GB/s | — | 14.4 TB/s | 14.4 TB/s |
| NVIDIA NVSwitch | NVLink 5 スイッチ | — | NVLink 5 スイッチ | NVLink 5 スイッチ |
| NVSwitch GPU間帯域 | — | — | 1.8 TB/s | 1.8 TB/s |
| 最大熱設計電力 (TDP) | — | 最大 600W(設定可能) | — | — |
* 構造的スパース性を含む値です。 ** FP4は「スパース | 密」の順で記載。 H200 NVLは前世代(Hopper)製品のため一部行で規格が異なります。
研究開発から本番運用まで
幅広いワークロードに最適化
ディープテック・学術研究から、データサイエンス、AIアプリ開発まで。1台で多様な用途をカバーします。

製品仕様 — DGX Station(GWS-GB300SM)
Supermicro ARS-511GD-NB-LCC ベース/Super AI Station(NVIDIA GB300 搭載)
| プロセッサ / GPU | |
|---|---|
| チップセット | NVIDIA GB300 Grace Blackwell Ultra Desktop Superchip |
| CPU | NVIDIA 72コア Grace ARM CPU(Neoverse V2) |
| GPU | NVIDIA Blackwell B300 GPU(252GB HBM3e)/オンボード1基 |
| CPU-GPU 相互接続 | NVIDIA NVLink-C2C |
| FP4 演算性能 | 最大 20 PFLOPS |
| 対応モデル規模 | 最大 1兆(1T)パラメータ級モデル |
| メモリ | |
| 統合メモリ | 最大 748GB コヒーレント(CPU側 496GB LPDDR5X + GPU側 252GB HBM3e) |
| CPUメモリ | 4× 128GB SOCAMM LPDDR5X モジュール(合計 496GB/396GB/s) |
| GPUメモリ帯域 | 252GB HBM3e / 8TB/s |
| ネットワーク / I/O | |
| ネットワーク | 2× 400GbE(オンボード ConnectX-8 SuperNIC、最大 800Gb/s) |
| 管理LAN | 1× 10GbE RJ45 + 1× 1GbE IPMI |
| USB / 映像 | 前面・背面 USB Type-A / Type-C、1× mini-DisplayPort |
| ストレージ / 拡張 | |
| ドライブ | 2× M.2 2280(OS用 RAID)+ 2× M.2 2280(学習データ用)/ PCIe 5.0 NVMe |
| 拡張スロット | 1× PCIe 5.0 x16(HHHL)+ 2× PCIe 5.0 x8(FHHL) |
| 冷却 / 電源 / 筐体 | |
| 冷却 | クローズドループ ダイレクト液冷(D2C Cold Plate) |
| 電源 | 1600W Titanium Level(94%)電源/単相200V(AC200〜240V)を推奨します。 |
| フォームファクタ | 5U タワー(ラックマウント対応) |
| 寸法 | W 454.7 × H 218.4 × D 701 mm |
| 重量 | 約 40kg(本体) |
| ソフトウェア | |
| OS | Ubuntu 24.04+(NVIDIA AI Developer Tools プリインストール) |
| セキュリティ | Silicon Root of Trust(RoT)/NIST 800-193 準拠 |
※ 仕様は予告なく変更される場合があります。最終仕様・構成はお問い合わせください。
よくあるご質問
NVAIE(NVIDIA AI Enterprise)は付属しますか?
デスクサイドに設置できますか?電源の条件は?
動作音(騒音)はどの程度ですか?
GPUを追加で搭載できますか?
筐体デザインのカスタマイズや独自ブランド対応は可能ですか?
どんなユーザーに向けた製品ですか?
チームで1台を共有する最適な方法を教えてください。
- CPUとホストメモリは協調的に共有され、ユーザー単位でのハイパーバイザーによる強制クォータはありません。
- 増設したRTX PROカードでのMIG構成は現状サポート対象外です。
搭載OSについて教えてください。
- NVIDIA DCGM(Data Center GPU Manager)
- NVIDIA CUDA Toolkit
- NVIDIA Container Toolkit
- NVIDIA グラフィックスドライバ
- NVIDIA DOCA ソフトウェアフレームワーク
- NVIDIA Optimized Kernel
- NVIDIA GPUDirect Storage
DGX Spark を複数台の連結と比較して DGX Station を選ぶ理由は何ですか?
- DGX Spark 1台比:演算20倍(20 petaFLOPS FP4 / Sparkは1 petaFLOP)、コヒーレントメモリ5倍(748GB / 128GB)、メモリ帯域23倍
- DGX Spark 4台比でも:生演算5倍、メモリ・帯域とも上回る
- 2台構成:40 petaFLOPS(マルチSpark構成は4 petaFLOPS)
- データセンターのGB300 NVL72と同一のGB300アーキテクチャを持つ唯一のローカルシステムで、デスクからAIファクトリーへワークロードをシームレスに移植可能
増設できるPCIeカードは何がありますか?
- ディスプレイ出力用のNVIDIA RTX PRO 2000/4000 Blackwell SFF(ディスクリートGPU)
- 表示・フィジカルAI・ロボティクス・可視化など、レイトレや実時間グラフィックスが必要な用途向けのNVIDIA RTX PRO 6000 Blackwell Max-Q/6000 Blackwell Workstation Edition
製品サポート窓口はどこですか?
ハードウェア障害が発生した場合はどうなりますか?
AIアプリケーションやシステム構築もサポートされますか?
AIコンピューティングのエキスパート
国内有数のNVIDIA専門企業として、ハードウェアの選定から導入・運用まで一貫してご支援します。

NVIDIA エリートパートナー認定
NVIDIA Partner Network(NPN)で最高ランクのエリートパートナーに認定。Compute(DGX)と Visualization の各コンピテンシーを保有し、国内有数のNVIDIA専門企業として、AIコンピューティングの最前線を支えます。 Compute (DGX) / Visualization 保有

AIに最適化された
ハードウェアを提供
- AI学習・推論に特化した最新のGPUを提供
- 高速VRAMと最新アーキテクチャを常に採用
- その他、運用ツールの提供構築から運用支援まで、幅広く提供

業界標準としての
実績と信頼性
- AI学習用サーバーをはじめとしたGPU搭載システムに特化
- 研究機関・大学・企業に納品実績多数
- 生成AIと親和性の高いインダストリアルに対して多数の販売実績


