NVIDIA GB10 Grace Blackwell Superchip搭載パーソナル AI コンピューター NVIDIA DGX™ Spark



民間企業、政府機関、学術などの研究者がAIへの取り組みを強化するにつれ、AIの計算リソースに対するニーズが高まっている背景から、生成AIモデルのサイズや複雑さが増し、ローカルシステムでの開発が困難になっています。
複雑で大規模なモデルをローカルでプロトタイピング、チューニング、推論するには、大容量のメモリと大きな計算性能が必要になります。
複雑で大規模なモデルをローカルでプロトタイピング、チューニング、推論するには、大容量のメモリと大きな計算性能が必要になります。
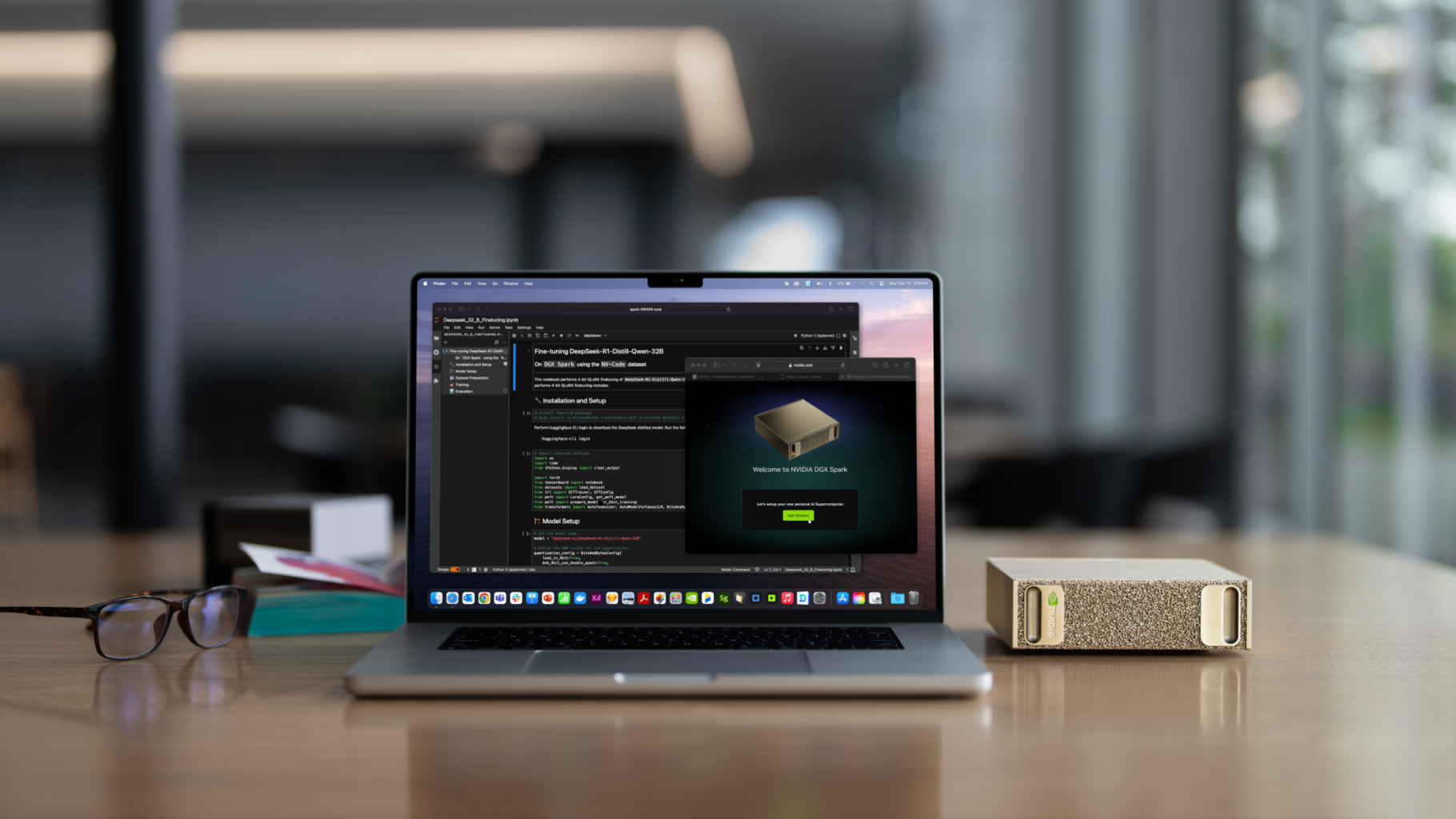
NVIDIA DGX™ Spark は世界最小の AI スーパーコンピューターで、多くの研究者、データ サイエンティスト、ロボティクス開発者、学生が生成 AI やフィジカル AIにおいて圧倒的なパフォーマンスと機能を提供します。
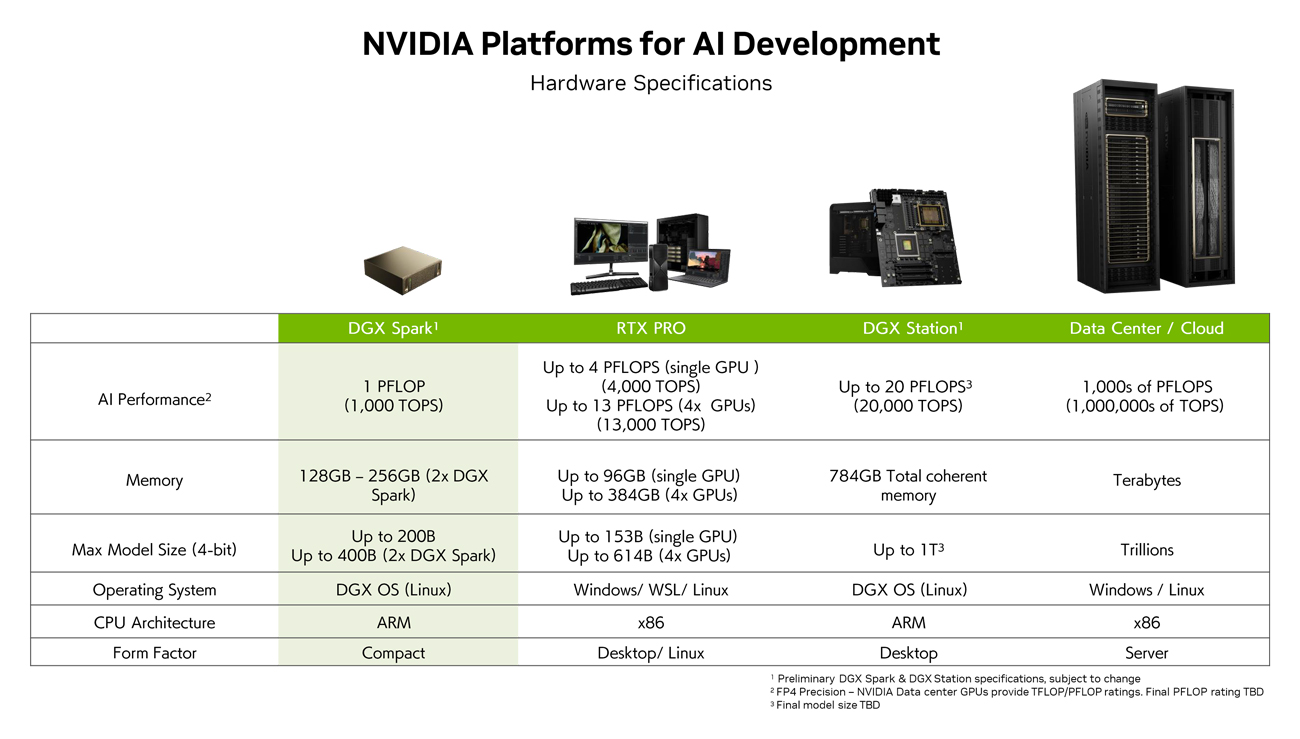
DGX Spark の内部には、デスクトップのフォーム ファクター向けに最適化された NVIDIA GB10 Grace Blackwell Superchip が搭載されています。GB10 は、第5世代の Tensor コア と、FP4 サポートを備えた強力な Blackwell GPU を搭載しており、NVIDIA Cosmos™ Reason 世界基盤モデルや NVIDIA GR00T N1 ロボット基盤モデルを含む最新の AIモデルによるファインチューニングと推論において、1 秒間に最大 1,000 兆回の AI 演算を可能にします。
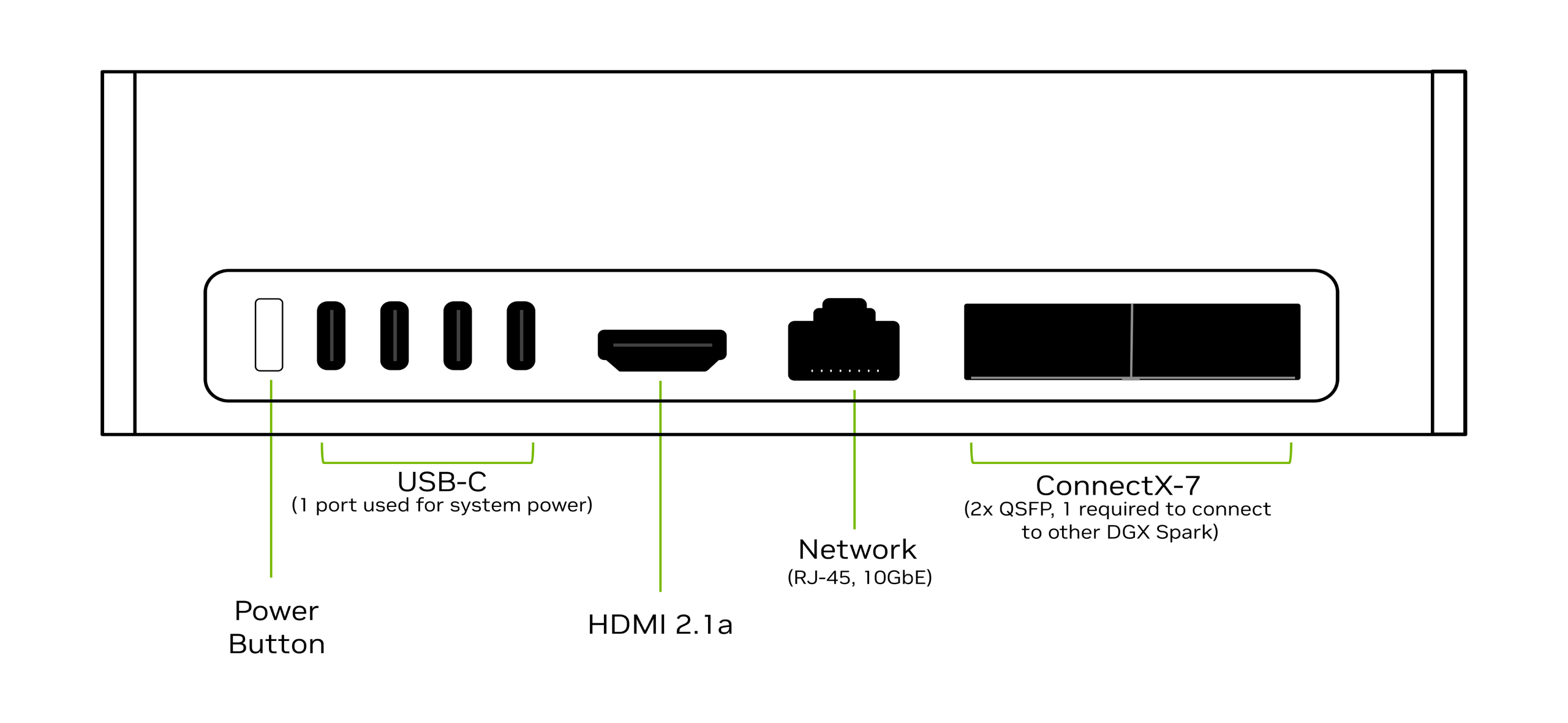
前段のGB10 Superchip は、NVIDIA NVLink™-C2C 相互接続技術により、第 5 世代 PCIe の 5 倍の帯域幅を持つCPU+GPU コヒーレント メモリ モデルで、GPU と CPU 間のデータにアクセスし、メモリを多用する AI 開発者のワークロード向けにパフォーマンスを最適化することができます。
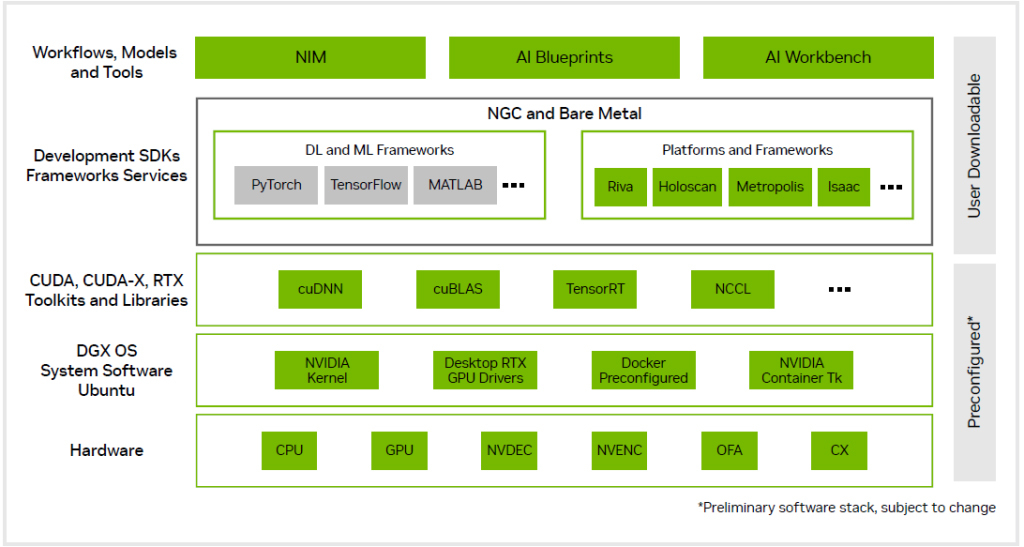
NVIDIA のフルスタック AI プラットフォームにより、DGX Spark ユーザーは、デスクトップから DGX CloudやあらゆるGPUクラウドやデータセンターインフラにシームレスにAIモデルを移動でき、ワークフローのプロトタイプを作成したり、ファインチューニングを行うなどの反復がこれまで以上に容易になります。
- NVLink C2C
- NVIDIA Grace
- Blackwell
- 20Core
- DDR5
- non-ECC